■ 인덱스 튜닝
*데이터를 엑세스 하는 방법 2가지
1. full table scan : /*+ full(테이블명) */
2. index scan
-index range scan : /*+ index(테이블명 인덱스명) */
-index unique scan : /*+ index(테이블명 인덱스명) */
-index full scan: /*+ index_fs(테이블명 인덱스명) */
-index fast full scan: /*+ index_ffs(테이블명 인덱스명) */
-index skip scan: /*+ index_ss(테이블명 인덱스명) */
-index merge scan: /*+ and_equal(테이블명 인덱스명) */
-index bitmap merge scan: /*+ index_combine(테이블명 인덱스명) */
■ table full scan(=full table scan)
테이블 전체를 스캔하는 데이터 엑세스 방법
*full table scan 이 인덱스 스캔보다 더 유리한 경우?
테이블에서 검색하려는 데이터의 양이 많을 때
(인덱스를 통해서 데이터를 검색하는 양이 많아서
오히려 느려질 때)
*full table scan 을 할 수 밖에 없는 경우
1. 병렬처리 할 때
예: select /*+ parallel(e 4) */ empno, ename, sal
from emp e
emp테이블을 4개의 프로세서가 나눠서 읽는다.
(일의 분담화)
2. 인덱스 생성할 때
예: create index emp_sal
on emp(sal);
3. 인덱스를 재구성 할 때
예: alter index emp_sal rebuild ;
왜 필요하냐면
본문내용 절반이 지워졌으면
인덱스도 해당내용을 까맣게 지워놓는다.
(없어지진 않는다. 죽은이파리 처럼 남아있는다.)
죽은이파리를 없애고 깔끔하게 정렬하기 위해
위의 재구성을 돌리고
이 때 full scan 한다.
■ 인덱스 재구성 테스트
"테이블의 데이터를 수정하게 되면 테이블의 데이터는
변경되지만 인덱스는 변경하지 않고 그냥 남아있게 된다."
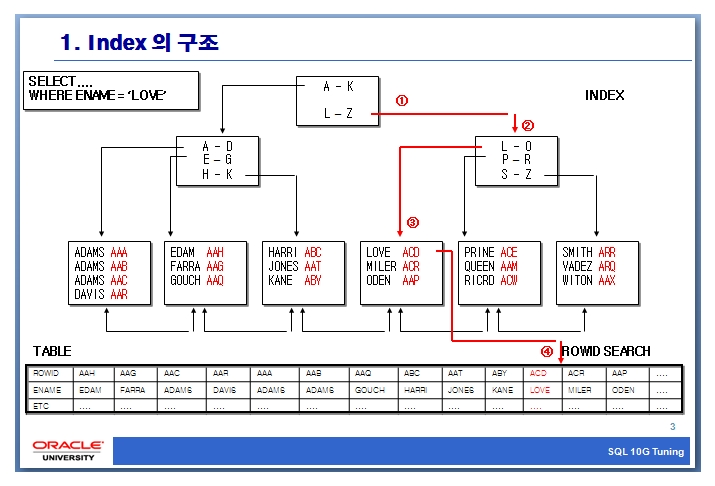
나무를 거꾸로 해놨다고 b tree 라고 함.
뿌리-가지-잎
3에서 love acd 중 acd 는 rowid
문제1.
사원 테이블에 이름에 인덱스를 걸고
emp_ename 인덱스의 데이터를 가져오게끔 아래와 같이
수행하시오
create index emp_ename
on emp(ename);
select ename, rowid
from emp
where ename > ' ';
문제2.
emp_ename b*tree 인덱스의 leaf 블럭이 몇 개가 있는지
확인하시오
analyze index emp_ename
validate structure;
select name, lf_rows, del_lf_rows
from index_stats;
이 내용이
root - branch - leaf 구조를 타고 내려오는데
14개 leaf 가
adams..allen ..............ward 순으로 나온다.
문제1의 답이 그렇게 나온거다.
문제3.
이름이 SCOTT 인 사원의 이름과 월급과 직업을 출력하는데
인덱스를 통해서 테이블을 엑세스 하는지 실행계획을 보고
확인하시오
위에 ename 으로 인덱스 한거 있음.
select ename, sal, job
from emp
where ename = 'SCOTT';

아래서부터 작업이 실행되 올라감.
rowid 거쳐서 가는걸 볼 수 있음.
문제4.
이름이 scott 인 사원의 이름과 월급과 직업을 출력하는
sql 을 작성하는데
full table scan 이 되게 힌트를 주시오.
select /*+ full(emp) */ ename, sal, job
from emp
where ename = 'SCOTT';
문제5. 위의 sql의 full table scan 실행계획과
인덱스 스캔 실행계획의 블럭의 차이가 얼마나 발생하는지
확인하시오
튜닝전:
select /*+ full(emp) */ ename, sal, job
from emp
where ename = 'SCOTT';
튜닝후:
select /*+ index (emp emp_ename) */
ename, sal, job
from emp
where ename = 'SCOTT';
문제6. 오라클 교육용 데이터중에 가장 큰 sales 테이블을
가지고 아래의 테이블을 생성하시오!
create table sales100
as
select rownum empno, s.*
from sales s;
문제7. sales100의 사원번호가 56071 번인 사원의
모든 컬럼을 출력하는 쿼리를 작성하고
읽어들인 블럭의 갯수를 확인하시오
select *
from sales100
where empno = 56071;
cmd 에서
set autot traceonly expain;
블럭수 5600개 확인가능
문제8. sales100 의 사원번호에 인덱스를 걸고
위의 sql 을 실행해서 인덱스 스캔을 하는지 확인을 하고
블럭의 갯수를 확인하시오
create index sales100_empno
on sales100(empno);
select *
from sales100
where empno = 56071;
블럭수가 42개로 확 줄어든다.
문제9. KING의 이름을 JACK 으로 변경하시오
(ENAME 에 인덱스 걸어 둔 상태임)
*INDEX 의 처리상황을 이해하기 위한 문제*
update emp
set ename = 'JACK'
where ename = 'KING';
commit;
테이블의 경우는 데이터가 KING -> JACK 으로
바로 변경이 되나
인덱스는 KING 리프블럭(LEAF BLOCK)
그냥 두고(검게, 죽은이파리화)
JACK 이라는 리프블럭을 추가한다.(abcd순서에 맞게)
analyze index emp_ename
validate structure;
select name, lf_rows, del_lf_rows
from index_stats;
이걸 돌려보면
잭이 추가되어
14+1=15 가 되었고
그 중 죽은 이파리 하나 생긴걸 볼 수 있다.
계속 쌓이니까 가지치기, 즉 재정리를 해준다
*인덱스 재구성 명령어
alter index emp_ename rebuild;
다시 인덱스 확인하기 위해
analyze index emp_ename
validate structure;
select name, lf_rows, del_lf_rows
from index_stats;
**validate : 유효성을 검사하다

죽은이파리가 사라진걸 볼 수 있다.
■ index range scan : /*+ index(테이블명 인덱스명) */
문제10. 월급이 3000 인 사원의 이름과 월급을 출력하는
sql 을 작성하는데
실행계획이 index range scan 이 되도록 인덱스를 걸고
작성하시오
create index emp_sal
on emp(Sal);
select /*+ index(emp emp_sal) */
ename, sal
from emp
where sal = 3000;
목차-페이지
인덱스-rowid
sal 걸어둔 인덱스 찾아서 3000 검색
테이블로 가서 3000 에 대한 rowid 검색
그리고 값 출력
문제10.(점심시간문제)
인덱스가 목차찾고 rownum 찾는 걸 증명하시오
select /*+ index asc (emp emp_sal) */
sal, rowid
from emp
where sal>0;
select rowid, ename
from emp;
문제11. 우리반 테이블에 이름에 인덱스를 걸고
아래의 sql 이 인덱스를 통해서 어떻게 테이블의
데이터를 엑세스 하는지 그림으로 그리시오
create index emp2_ename
on emp2(ename);
select ename, age, major
from emp2
where ename = '서일'
select ename, rowid
from emp2
where ename > ' ';
emp2_ename 인덱스 --------------------emp2 테이블
문제12.
통신사 컬럼에 인덱스를 생성하시오!
create index emp2_telecom
on emp2(telecom);
문제13.
이름이 서일이고 통신사가 sk 인 학생의
이름,통신사,나이,전공을 출력하시오
select ename, lower(telecom), age, major
from emp2
where ename = '서일' AND lower(telecom) = 'sk'
*현재 이름,텔레콤에 인덱스가 설정되어있다.
위의 2개의 인덱스 중에 어느 컬럼의 인덱스를 사용할까?
이름이다.
왜냐하면
이름 컬럼에 중복내용이 없으니까.
문제14. 아래의 sql 인덱스가 한번은 ename의 인덱스를 타게
힌트를 주고
또 한번은 telecom 의 인덱스를 타게끔 힌트를 주시오.
select ename, lower(telecom), age, major
from emp2
where ename = '서일' AND lower(telecom) = 'sk'
select /*+ index (emp2 emp2_name) */
ename, lower(telecom)
from emp2
where ename = '서일' AND lower(telecom) = 'sk';
select /*+ index (emp2 emp2_telecom) */
ename, telecom
from emp2
where ename = '서일' AND telecom = 'sk';
힌트를 통해서 제어를 한다.
***lower 빼니까 telecom 타서 인덱스돌아감.
lower(telecom)을 갖고오는건지
함수를 쓰라는건지 컴퓨터가 알 수 없음.
문제15.아래의 sql 을 튜닝하시오
튜닝전: select ename, telecom, age
from emp2
where lower(telecom) = 'sk';
튜닝후:
update emp2
set telecom = 'sk'
where telecom = 'SK';
select ename, telecom, age
from emp2
where telecom = 'sk';
***lower 지운게 튜닝....
****point 는 좌변을 가공하지 말아라
문제16. 아래의 sql 을 튜닝하시오
튜닝전:
select ename, age, telecom
from emp2
where telecom||age='sk26';
튜닝후:
select ename, age, telecom
from emp2
where telecom ='sk'
and
age = 26;
알아서 텔레콤에 걸어둔 인덱스 타고 작업함.
※자리마다 실행계획이 틀려지는 이유는?
자리마다 옵티마이져가 만드는 실행계획이 달라서 이다.
왜 다르냐면?
옵티마이져에게 줘야하는 정보가 부족해서 그렇다
emp2 테이블에 대한 분석정보를 생성해서 알려줘야 한다.
-emp2에 대해서 분석하겠다.
analyze table emp2 compute statistics;
-emp2 테이블의 분석정보가 언제 생성되었는지
확인하는 방법
select table_name, last_analyzed
from user_tables;
last_analyzed 에 날짜값 나오면 분석된거임.
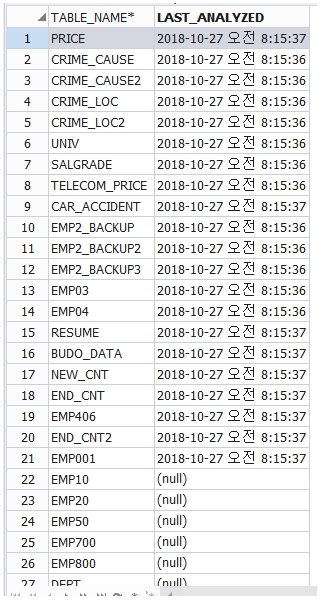
분석정보를 갱신해서 줘야
옵티마이져가 수행을 잘 해준다.
최신분석정보 안주면 말을 안 들어서 힌트 주고 그래야함.
문제17. 아래의 sql 을 튜닝하시오
(full table scan 이 아니라 index range scan 이 되게 하세요)
튜닝전:
select ename, sal, hiredate
from emp
where to_char(hiredate, 'rr/mm/dd') = '81/11/17';
튜닝후:
create index emp_hiredate
on emp(hiredate);
select ename, sal, hiredate
from emp
where hiredate = to_date('81/11/17', 'rr/mm/dd');
■ 결합 컬럼 인덱스
하나의 컬럼으로 인덱스를 구성한게 아니라
여러개의 컬럼으로 인덱스를 구성한 것
예:
create index emp_deptno_sal
on emp(deptno, sal);
select deptno, sal, rowid
from emp
where deptno > 0;

테이블 스캔안하고
인덱스만 스캔 한 걸 볼 수 있다.
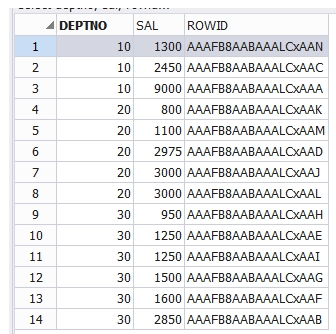
이 결과 자체가 인덱스 수행 내역이라고 보면 된다.
문제18. 아래의 sql 을 튜닝하시오
(그룹함수 쓰지 말고 인덱스로만
원하는 결과를 볼 수 있게 하시오)
튜닝전: select deptno, max(sal)
from emp
where deptno = 20
group by deptno;
튜닝후:
select /*+ index_desc (emp emp_deptno_sal) */
deptno, sal
from emp
where deptno = 20
and
rownum = 1;
예전거
튜닝전:
select ename, sal
from emp
where sal = (select max(Sal)
from emp);
튜닝후:
select /*+ index_desc (emp emp_sal) */
ename, sal
from emp
where deptno = 20
and
rownum = 1;
문제19. 아래의 sql을 튜닝하시오
(필요한 인덱스 알아서 생성하시오)
튜닝전:
select job, min(sal)
from emp
where job= 'SALESMAN'
group by job;
튜닝후:
create index emp_job_sal
on emp(job,sal);
select /*+ index_asc (emp emp_job_sal) */
job, sal
from emp
where job = 'SALESMAN'
and
rownum =1;
문제20. 아래의 sql 을 튜닝하시오
튜닝전:
select deptno, sum(sal)
from emp
group by deptno;
튜닝후:
-index full scan: /*+ index_fs(테이블명 인덱스명) */
-index fast full scan: /*+ index_ffs(테이블명 인덱스명) */
2개 같은건데 ffs가 더 빠릅니다.
select /*+ index_ffs (emp emp_deptno_sal) */
deptno, sum(sal)
from emp
group by deptno;
인덱스 안탐..........................................
※ index fast full scan 이 되려면 deptno 또는 sal 에
not null 제약이 걸려 있어야 한다.
책으로 따지면 빈페이지가 없음을 보장해줘야 한다.
alter table emp
modify deptno not null;
select /*+ index_ffs (emp emp_deptno_sal) */
deptno, sum(sal)
from emp
group by deptno;
where deptno is not null 이라고 줘도 된다.
F7 로 확인하면 빨간게 뜨긴 하는데
index탄 full scan 이라고 나온다.
문제21.
아래의 sql 을 튜닝하시오
(인덱스도 알아서)
튜닝전:
select job, count(*)
from emp
group by job;
튜닝후:
create index emp_job
on emp(job);
alter table emp
modify job not null;
select /*+ index_ffs (emp emp_job) */
job, count(*)
from emp
group by job;
■ 결합 컬럼 인덱스의 특징
" 결합 컬럼 인덱스의 첫번째 컬럼이
where 절에 존재해야
결합 컬럼 인덱스를 엑세스 할 수 있다."
*scott 유저가 가지고 있는 인덱스 리스트 조회
select index_name, column_name, column_position
from user_ind_columns
where table_name = 'EMP'
order by index_name, column_position;
drop table emp 해서 다 날리고
다시 생성
문제22. 월급이 1250 인 사원의 이름,월급, 부서번호를
출력하고 실행계획을 확인하시오
create index emp_deptno_sal
on emp(deptno, sal);
select ename, sal, deptno
from emp
where sal = 1250;
이렇게 하면 풀스캔 뜬다
왜 냐 하 면
인덱스 생성시 deptno, sal 순서로 만들었다.
그래서 range index 는
where 절에 deptno 넣을 때만 인덱스 탄다.
이걸 가능하게 하는 방법은
index skip scan !!!!!
select /*+ index_ss(emp emp_deptno_sal) */
ename, sal, deptno
from emp
where sal = 1250;
select detpno, sal, rowid
from emp
where sal =1250;
*index skip scan*
deptno_sal
where =1250
에 skip scan 을 돌리면
각 부서번호마다 돌면서 1250을 찾는다
그러다
부서번호 30에서
1250 다 찾으면 작업중이던 부서번호 30에서는 나간다.
(중복을 배제 하는거 아님)
부서번호가 10,20,30 .....50 까지 있으면
50까지는 다 1250을 찾는다.

문제23. 아래 sql 을 튜닝하시오
drop index emp_deptno_sal;
create index emp_job_sal
on emp(job, sal);
위 인덱스의 구조
튜닝전
select ename, job, sal, deptno
from emp
where sal = 3000;
튜닝후
select /*+ index_ss (emp emp_job_sal) */
ename, job, sal, deptno
from emp
where sal = 3000;
문제24.(오늘의 마지막 문제)
demobld 를 돌리고 이름에 index 를 거시오
그리고 아래의 sql 을 튜닝하시오
튜닝전:
select ename, sal, job, deptno
from emp
where ename like '%EN%'
or
ename like '%IN%';
튜닝후:
create index emp_ename
on emp(ename);
1. 이름에 EN 또는 IN 을 포함하고 있는 사원들의
데이터의 ROWID 를 EMP_ENAME 에서
빠르게 스캔해서 가져오는
쿼리를 만든다.
2. 튜닝전의 쿼리를 in line view 로 만들고
rowid 를 연결고리로 해서
emp 와 조인한다.
alter 써서 하는 방법:
alter table emp
modify ename not null;
select ename, sal, job, deptno
from emp e,
(select /*+ index_ffs(emp emp_ename) */
rowid, ename
from emp
where ename like '%EN%'
or
ename like '%IN%') ee
where e.rowid = ee.rowid;
where 절에 인덱스 조건 거는 방법:
select e1.ename, e1.sal, e1.job, e1.deptno
from emp e1, ( select /*+ index_ffs(emp emp_ename) */ rowid
from emp
where ename like '%EN%'
or ename like '%IN%' ) e2
where e1.rowid = e2.rowid
and
ename > ' ';
선생님의 merge 인덱스 방법:
select /*+ rowid(e) use_nl(v e) */
e.ename, e.sal, e.job, e.deptno
from emp e,
(select /*+ no_merge index_ffs(emp emp_ename) */
rowid as rn
from emp
where ename like '%EN%'
or ename like '%IN%') v
where e.rowid = v.rn;
※ no_merge 힌트?
in line view 를 해체하지 말아라
'sql_tuning' 카테고리의 다른 글
| 5. 파티셔닝 (0) | 2019.04.02 |
|---|---|
| 4. 서브쿼리 튜닝 (0) | 2019.04.02 |
| 3. 조인 튜닝 (0) | 2019.04.02 |
| 2-1. 인덱스 엑세스 방법 (0) | 2019.04.02 |
| 1. sql 튜닝이란 무엇이고 왜 배워야 하는가? (0) | 2019.04.02 |

