1회 마지막 문제답으로
merge 인덱스 소개:
select /*+ rowid(e) use_nl(v e) */
e.ename, e.sal, e.job, e.deptno
from emp e,
(select /*+ no_merge index_ffs(emp emp_ename) */
rowid as rn
from emp
where ename like '%EN%'
or ename like '%IN%') v
where e.rowid = v.rn;
※ no_merge 힌트?
in line view 를 해체하지 말아라
■index 엑세스 방법 7가지
1. index range scan
2. index unique scan
3. index full scan
4. index fast full scan
5. index skip scan
6. index merge scan
7. index bitmap merge scan
■ index unique scan
"unique 한 인덱스를 엑세스 하는 스캔 방법"
*unique 인덱스의 종류 2가지
1. unique 인덱스 : 인덱스를 걸 컬럼의 데이터가 unique 한 데이터인
경우의 생성될 인덱스
예: emp 테이블에서 unique 한 컬럼은 empno
2. non unique 인덱스: 인덱스를 걸 컬럼의 데이터가 중복되어 있는
경우의 생성될 인덱스
예: emp 테이블에서 non unique 한 컬럼은 deptno, job
*unique 인덱스 생성 방법 2가지
1. 명시적 방법:
create unique index emp_empno
on emp(empno);
2. 암시적 방법:
primary key 와 unique 제약을 걸면
자동으로 unique 인덱스가 생성.
*테스트
1. demoble.sqp 스크립트를 수행하시오
2. create unique index emp_empno
on emp(empno);
create index emp_sal
on emp(sal);
3. select index_name, uniqueness
from user_indexes
where table_name = 'EMP';
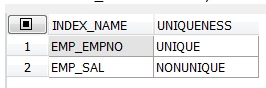
4. 다시 demobld
5. insert into emp (empno, ename, sal)
values (7788, 'SCOTT', 3000);
6. unique index 를 걸어보아라
create unique index emp_empno
on emp(empno);
에러나옴. 중복키 있어서.
※중복된 데이터가 있으면 unique 인덱스가 안 걸립니다.
다시 말하면 unique 인덱스가 걸리는 컬럼은
그 컬럼에 중복된 데이터가 하나도 없다는 것이다.
■암시적 방법 유니크 인덱스
문제25. 데모벨 스크립트를 다시 돌리고,
사원 테이블의 empno 에 primary key 제약을 걸고
unique 인덱스가 자동으로 생성되었는지 확인하시오!
alter table emp
add constraint emp_empno_pk primary key(empno);
select index_name, uniqueness
from user_indexes
where table_name = 'EMP';
문제26. 위의 상황에서 이름에 non unique index 를 걸고
아래의 sql 을 수행하면 어느 컬럼의 인덱스를 사용할 것 인가?
create index emp_ename
on emp(ename);
select empno, ename, sal, job
from emp
where empno = 7788
and ename = 'SCOTT';
***
non unique index = range index
VS
unique index
둘 중 어느 것을 타는가?
*오라클이 우선순위를 non unique 인덱스보다
unique 인덱스를 훨씬 높게 준다.
*오라클의 수행작업 우선순위 표
1. rowid 에 의한 데이터
:
:
10. full table scan
문제27. 우리반 테이블 이름에 unique 제약을 걸고
unique 인덱스가 생성되었는지 확인하시오
alter table emp2
add constraint emp2_ename_pk primary key(ename);
select index_name, uniqueness
from user_indexes
where table_name = 'EMP2';
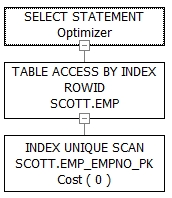
문제28. 사원번호가 7788 번인 사원의 사워번호, 이름, 월급을
출력하는 sql 의 실행계획을 보고 index unique scan 했는지
확인하시오!
select empno, ename, sal
from emp
where empno = 7788;
select empno, rowid
from emp;

range scan(=non unique) 같은 경우는 7788찾고
밑으로 더 스캔한다음에
rowid 로 넘어가는데,
unique index 는 7788 찾자 마자 바로 빠져나가서
훨씬 빠르다.
※ unique 인덱스는 인덱스에서 딱 한 건만 읽는다.
■index merge scan
"데이터를 검색할 때
두 개의 인덱스를 동시에 사용해서
더 큰 시너지 효과를 보는 스캔 방법"
*현업에서 많이 쓰이지 않아서
간단하게 테스트 돌리고 넘어가겠다고 하셨음.
테스트:
create index emp_job
on emp(job);
create index emp_deptno
on emp(deptno);
select empno, ename, job, deptno
from emp
where job ='SALESMAN',
and deptno = 30;
실행계획 확인

select count(*) form emp where deptno
실행계획을 확인해보니 job 의 인덱스를 탔는데
만약 두 개의 인덱스를 동시에 사용하고 싶다면?
select /*+ and_equal (emp emp_deptno emp_job) */
empno, ename, job, deptno
from emp
where job = 'SALESMAN' and deptno = 30;
이 쿼리는
책 안에 목차가 2개있어서 그 2개를 가지고
찾아내라는 명령어다.
하지만
emp_job 인덱스만 타고 실행한 쿼리보다
블럭수가 더 많다.
그런데
대용량 작업할 때 상황에 따라
각각 다르게 나온다. 봐서 알아서 잘 쓰면 된다.
요즘은 merge index 를 안 쓰는 이유가
bitmap merge가 훨씬 성능이 좋아서다.
■index bitmap merge scan
" 두 개의 인덱스를 사용하는 것은 index merge scan 과 똑같은데,
다른 것은 인덱스를 bit 로 변환해서
사이즈를 확 줄인 다음에 스캔한다는 것이 차이점이다."
예: 책 앞에 목차가 10장, 책 뒤의 목차도 10장 이라고 하면
index merge scan 은 10장, 10장 두개를 같이 읽어서
테이블에 찾아갈 rowid 를 알아낸다면
index bitmap merge scan 은 10장을 1장으로 요약한다.
앞 뒤 1장, 1장 두 개를 같이 읽어서 테이블에 찾아갈 rowid 를
알아낸다.
보고서 10장 짜리를 1장으로 요약했다고 생각하면 된다.
테스트:
alter table emp
modify job not null;
alter table emp
modify deptno not null;
***not null 제약 안 주면 null 있나없나
찾으려고 또 스캔값 늘어남.
select /*+ index_combine(emp emp_job emp_deptno) */
empno, ename, job, deptno
from emp
where job = 'SALESMAN' and deptno = 30;
답이 나오지 않습니다 !
12c 에서 지원합니다
문제29. 아래의 sql 을 튜닝하시오
create index emp2_ename
on emp2(ename);
튜닝전:
select ename, age, major
from emp2
where substr (ename, 1,1 ) = '김';
튜닝후:
SELECT /*+ index (emp2 emp_ename) */
ename, age, major
from emp2
where ename LIKE '김%';
문제30. 아래의 sql 을 튜닝하시오
*의외로 놓친다**
create index emp2_age
on emp2(age);
튜닝전:
select ename, age, major
from emp2
where age like '4%';
튜닝후:
CREATE INDEX emp2_age_func
ON EMP2(TO_CHAR(age));
select /*+ index (emp2 emp2_age_func) */
ename, age, major
from emp2
where age like '4%';
데이터 타입 맞춰주는게 무척 중요하다
나중에 빅데이터 다룰 때
이것만 맞춰줘도 실행시간이 많이 줄어든다.
****
select /*+ index (emp2 emp2_age) */
ename, age, major
from emp2
where TO_CHAR(age) like '4%';
이렇게 돌려도
access full. 이미 age를 문자화 시키는게 풀작업
To_char 안하는게 맞지않나??
그럴려고 함수인덱스쓴건데???
*sql trace 실행계획 확인하는 방법
문제31.(점심시간문제)
*전날 마지막 문제 참고해서*
아래의 sql 을 튜닝하시오
전공에 통계가 포함되어져 있는 학생들의
이름, 전공을 출력하시오!
(ename, job 에 인덱스 걸려있는데
Job 에만 fast full index 타게끔 하고,
2개 테이블을 use_nl 로 조인하시오.)
튜닝전:
select ename, major
from epm2
where major like '%통계%';
튜닝후:
create index emp2_major
on emp2(major);
select/*+ rowid(e) use_nl(v e) */
e.ename, e.major
from emp2 e,
(select /*+ no_merge index_ffs(emp2 emp2_major) */
rowid as rn
from emp2
where major like '%통계%') v
where e.rowid = v.rn;
지금 전제가 인덱스2개 만든거다.(ename, major)
인덱스 하나만 fast full scan 해서 값 뽑아내는게 목적.
V테이블 절에 2개 인덱스 합치지 말고 풀스캔하라고
No_merge index_ffs (emp emp_major)로 힌트먹이고
지정인덱스 major 를 이용해서 Where 조건절 설정,
Nested loop 로 조인힌트 먹이고
(힌트절에 rowid가 왜 들어가는지는 모르겠음.)
Where 절에 연결고리해서 값 출력.
문제32. 아래의 sql을 튜닝하시오
튜닝전:
select ename, sal
from emp
where sal = (select max(sal)
from emp);
튜닝후:
select /*+ indesx_desc (emp emp_sal) */
ename, sal
from emp
where sal > 0
AND ROWNUM =1 ;
문제33.아래의 sql 을 튜닝하시오
튜닝전:
select ename, hiredate
from emp
where hiredate = (select min(hiredate)
from emp) ;
설명: 가장 먼저 입사한 사원의
이름과 입사일을 출력하는 문제인데
위의 sql 은 emp를 2번 엑세스 하고 있는
악성 sql 이다.
그래서 인덱스를 통해서 데이터를 엑세스 하게끔해서
emp 를 1번만 엑세스 하게 하려면?
튜닝후:
create index emp_hiredate_func
on emp(to_char(hiredate) );
select /*+ index_asc (emp emp_hiredate_func) */
ename, hiredate
from emp
where hiredate < to_date('9999/12/31', 'rrrr/mm/dd')
and
rownum = 1;
문제34. 아래의 sql을 튜닝하시오
튜닝전:
select ename, sal
from emp e
where sal > (select avg(Sal)
from emp s
where s.deptno = e.deptno);
튜닝후:
SELECT e.ename, e.sal
FROM EMP e,
(SELECT deptno, AVG(sal)평균
FROM EMP
GROUP BY deptno) ee
WHERE e.deptno = ee.deptno
AND sal > 평균
ORDER BY ename;
블럭수 6개
SELECT ename, sal
FROM (
SELECT ename, sal, AVG(sal) OVER(PARTITION BY deptno) 평균
FROM emp)
WHERE sal > 평균 ;
블럭수 3개
문제35. 아래의 sql 을 튜닝하시오
튜닝전:
select ename, sal, e.job
from emp e
where 4 < (select count(*)
from emp s
where s.job = e.job);
튜닝후:
우용답
Select ename, sal,job
From (select ename,sal,job, count(*) over (partition by job ) coun
From emp)
Where coun >= 4;
SELECT ename, sal, e. job
FROM EMP e,
(SELECT job, COUNT(*)직업수
FROM EMP
GROUP BY job) ee
WHERE e.job = ee.job
AND 직업수 >= 4 ;
문제36. 아래의 sql 을 튜닝하시오
튜닝전:
select job, sum(sal)
from emp
group by job
union
select null as job, sum(Sal)
from emp;
튜닝후:
select job, sum(sal)
from emp
group by grouping sets(job, () );
또는 rollup
■expand_gset_to_union
문제37. 아래의 sql 을 union all 로 변경하시오
튜닝전:
select deptno, job, avg(sal)
from emp
group by grouping sets( (deptno), (job) );
139블럭
튜닝시도
select /*+ expand_gset_to_union */
deptno, job, avg(sal)
from emp
group by grouping sets( (deptno), (job) );
블럭수 54개로 줄어든다.
※설명: expand_gset_to_union 힌트는?
오라클 옵티마이져에게 sql 을 네가 union all 로
작성해라 라고 명령을 내리는 힌트
튜닝후:
select deptno, null, avg(sal)
from emp
group by deptno
union all
select null, job, avg(sal)
from emp
group by job;
44블럭
Expand_gset_to_union 이라는 힌트쓰면
Union all 써서 일일이 쿼리 안짜도 됨.
'sql_tuning' 카테고리의 다른 글
| 5. 파티셔닝 (0) | 2019.04.02 |
|---|---|
| 4. 서브쿼리 튜닝 (0) | 2019.04.02 |
| 3. 조인 튜닝 (0) | 2019.04.02 |
| 2. 인덱스 튜닝 (0) | 2019.04.02 |
| 1. sql 튜닝이란 무엇이고 왜 배워야 하는가? (0) | 2019.04.02 |

