■ 조인 문장 튜닝
*조인의 방법 3가지
힌트
1. nested loop 조인 : use_nl
2. hash 조인 : use_hash
3. sort merge 조인 : use_merge
■ nested loop 조인
중첩 루프 조인
문제38. 이름, 부서위치를 출력하는 조인문장의
실행계획을 보고
emp 테이블을 먼저 읽고 dept 랑 조인했는지
dept 테이블을 먼저 읽고 emp 랑 조인했는지 알아내시오
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno;

dept -> emp -> hash join -> select statement
얇은책과 두꺼운책을 조인해서 결과를 보겠다는 거임.
그래서 얇은책 먼저 ㄱㄱ
옵티마이져가 알아서 똑똑하게 했음.
■ nested loop 조인
"조인하려는 데이터의 양이 작은 경우는 nested loop 조인이
유리하다"
dept ---------------> emp
10 10
20
30
40
4건 14건
ㄱ 자로 훑어 내려가는데
꺾을때가 오래 걸림.
경우의 수로만 따지면 56개 똑같지만
dept로 출발하면 4번만 꺾으면 되서
더 빠르다.
select /*+ use_nl(d e) */
e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno ;

hash 조인에서 nested loops 로 바뀐걸 볼 수 있다.
*조인 순서를 변경하는 힌트
1. ordered : from 절에서 기술한 순서대로 조인하겠다.
2. leading : leading 힌트 안에 쓴 테이블 순서대로 조인하겠다.
select /*+ ordered use_nl(d e) */
e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno ;
emp 먼저 드라이빙 하라고 하는것임.
블럭수 45개
select /*+ ordered use_nl(d e) */
e.ename, d.loc
from dept d, emp e
where e.deptno = d.deptno ;
from절에 있는 걸 바꾸면
드라이빙 순서 바꿀 수 있다.
dept 먼저 돌리면
블럭수 28개
*ordered 는 from절에 직접써서 순서를 바꿔야 해서 귀찮다.
*조인 순서를 변경하는 힌트
1. ordered : from 절에서 기술한 순서대로 조인하겠다.
2. leading : leading 힌트 안에 쓴 테이블 순서대로 조인하겠다.
*leading 을 이용해본다.
select /*+ leading(e d) use_nl(d e) */
e.ename, d.loc
from dept d, emp e
where e.deptno = d.deptno ;

from절과 상관없이 leading 에 먹인 순서대로
출력된다.
문제39. emp와 salgrade와 dept를 조인해서
이름, 월급, 부서위치, 급여등급을 출력하시오.
select e.ename, e.sal, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and e.sal between s.losal
and s.hisal;
문제40. 위의 조인문장의 조인순서와 조인방법을
아래의 방법으로 수행하시오
조인순서: salgrade ----> emp-------------> dept
↑ ↑
조인방법: nested loop조인 nested loop 조인
SELECT /*+ leading(s e d) use_nl(e) use_nl(d) */
e.ename, e.sal, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and e.sal between s.losal
and s.hisal;
salgrade 는 leading 에 의해 제일먼저 드라이빙되서
use_nl(s) 로 언급 안해도 됨.
문제41.위의 sql 이 아래와 같은 조인순서로 실행되게하시오.
조인순서: dept----------> emp-------------> salgrade
↑ ↑
조인방법: nested loop조인 nested loop 조인
select /*+ leading( d e s ) use_nl(e) use_nl(s) */
e.ename, e.sal, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and
e.sal between s.losal
and s.hisal;
*nested loop 조인 걸면 뒤에 테이블값으로 표시한다
dept---------->emp
↑
nested loop
use_nl(e)
자료 큰거로 돌려 봅시다.
create table sales600
as
select *
from sales;
create table customers600
as
select *
from customers;
sales600 은 count 90만개
cunstomers600은 count 5만개
SELECT COUNT(*)
FROM sales600 s, customers600 c
WHERE s.cust_id = c.cust_id
AND c.country_id = 52790
AND s.time_id BETWEEN TO_DATE('1999/01/01','YYYY/MM/DD')
AND TO_DATE('1999/12/31','YYYY/MM/DD') ;
블럭수 5966개
SELECT /*+ leading(c s) use_nl(s) */
COUNT(*)
FROM sales600 s, customers600 c
WHERE s.cust_id = c.cust_id
AND c.country_id = 52790
AND s.time_id BETWEEN TO_DATE('1999/01/01','YYYY/MM/DD')
AND TO_DATE('1999/12/31','YYYY/MM/DD') ;
위 쿼리가 use_nl 에 맞는 코딩이지만
값이 엄청 느리다.
(nested loop 는 작은값에만 유리함)
use_nl(c) 로 하면 빨리 값이 출력되긴 하나
leading 절에 반하는 명령.(즉 잘못된 명령)
옵티마이져가 내 명령 이상해서 자기 맘대로
hash 로 뽑은것.
문제42.(오늘의 마지막 문제)
아래의 sql 을 튜닝하시오
(무조건 nested loop 조인으로 수행하되
가장 좋은 조인 순서를 결정하시오!)
create table sales100 as select * from sales;
create table times100 as select * from times;
create table products100 as select * from products;
튜닝전:
select /*+ leading(s t p) use_nl(t) use_nl(p) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)
and p.prod_name like 'Deluxe%'
group by p.prod_name, t.calendar_year;
카운트: sales100 91만개
times100 1800개
products100 72개
튜닝후:
순서는 p-t-s
create index times100_calendar_year_func
on times100(to_char(calendar_year) );
create index products100_name
on products100(prod_name);
select /*+ leading(p t s) use_nl(t) use_nl(s) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and TO_CHAR(t.CALENDAR_YEAR) = TO_DATE('2000', 'rrrr')
AND TO_CHAR(t.CALENDAR_YEAR) = TO_DATE('2001', 'rrrr')
and p.prod_name like 'Deluxe%'
group by p.prod_name, t.calendar_year;
그런데
where p.prod_name like 'Deluxe%;
이게 1건임.
select /*+ leading(s t p) use_nl(t) use_nl(p) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)
and p.prod_name like 'Deluxe%'
group by p.prod_name, t.calendar_year;
sales100 이랑 times100 은 time_id 로 조인
sales100 이랑 products100 이랑 pro_id 로 조인
(*times100 이랑 products100 은 조인된게 없음)
근데 출력조건이
times100에서 calendar 2000, 2001 과
products100 에서 'deluxe%' 를 충족시키는게 조건임.

선생님 설명+답
1. 각 테이블마다 주석처리로 테이블 건수를 적어줘야 함.
2. where 절에 뽑고자 하는 값의 건수도 적어줘야 함.
3. 출력하고자 하는 값 중 가장 작은 값부터
드라이빙 되게끔 순서를 결정한다.
(테이블 데이터수 순서가 아니라)
sales100 91만개
times100 1800개
products100 72개

select /*+ leading(s t p) use_nl(t) use_nl(p) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p ----918843, 1826, 72
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)----731
and p.prod_name like 'Deluxe%'-------------1
group by p.prod_name, t.calendar_year;
1. products100 테이블에서 p.prod_name like 'Deluxe%' 조건의 데이터
1건을 찾아낸다.
select count(*)
from products100
where prod_name like 'Deluxe%';
연결고리가 prod_id 이므로
몇번인지 확인한다.
select prod_id
from products100
where prod_name like 'Deluxe%';
2. 1건의 prod_id 47번을 sales100 테이블에 조인 시도를 한다.
(1건 밖에 없으므로 1번만 조인시도 한다.)
select count(*)
from products100 p, sales100 s
where p.prod_id = s.prod_id
and p.prod_name like 'Deluxe%';
3. prod_id 47번을 sales100 테이블에서 12837건을 찾아낸다.
select count(*)
from sales100
where prod_id = 47;
4. prod_id 12837건을 times100 테이블로 조인 시도를 한다.
(조인시도가 12837번)
select count(*)
from products100 p, sales100 s
where p.prod_id = s.prod_id
and p.prod_name like 'Deluxe%';
5. times100 테이블로 조인 시도한 12837건 중에
t.CALENDAR_YEAR in (2000,2001) 조건에
만족한 것만 결과로 출력된다.
나중에 배울건데,
중첩 루프 조인 -> 이중 루프문 프로그램
loop ...........
loop ...........
end loop;
end loop;
이렇게 루프문 안에 루프문 있는거.
연결고리를 유심히 보면서 nested loop를 시킨다.
p는 첫번째다.
t-p는 연결시키지 않는다.
■
1.sql 튜닝이란 무엇이고 왜 배워야 하는가?
2. 인덱스 튜닝
3. 조인 튜닝
4. 서브쿼리 튜닝
5. 기타 튜닝 방법들 소개
문제43.(어제 마지막 문제 이어서)
sales100 테이블의 prod_id 에 인덱스를 걸면
더 속도가 빨라지는지 확인하시오.
create index sales100_prod_id
on sales100(prod_id);
select /*+ leading(s t p) use_nl(t) use_nl(p) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)
and p.prod_name like 'Deluxe%'
group by p.prod_name, t.calendar_year;
딱히 안 빨라짐
인덱스 하나 더 걸어보겠음
create index times100_time_id
on times100(time_id);
빨라졌습니다
현업에서는
where 절의 연결고리에(time_id, prod_id)
primary key 를 걸어서
암시작 인덱스가 걸려있어서 빠르게 돌아가게 한다.
그 외에 index를 걸면 인덱스가 많아져서
오히려 느려진다.
그럼 여기서 걸어야 할 인덱스는
s.time_id ,
t.time_id,
s.prod_id,
p.prod_id
4개다
create index sales100_prod_id
on sales100(prod_id);
create index products100_prod_id
on products100(prod_id);
create index times100_time_id
on times100(time_id);
create index sales100_time_id
on sales100(time_id);
문제44. 아래의 sql 을 튜닝하시오
(조인방법은 무조건 nested loop 조인으로 하고
조인순서는 알아서 결정하고
인덱스도 알아서 생성하시오)
SELECT /*+ leading(c s) use_nl(s) */ COUNT(*)
FROM sales600 s, customers600 c -----918843, 55500
WHERE s.cust_id = c.cust_id
AND c.country_id = 52790 ---------------18520
AND s.time_id BETWEEN TO_DATE('1999/01/01','YYYY/MM/DD')
AND TO_DATE('1999/12/31','YYYY/MM/DD');
----------------247945
체크하고 주석달기:
(사실2개밖에 없어서 체크할 필요는 없음)
select count(*)
from sales600 s, customers600 c
where s.cust_id = c.cust_id;
918843건
c.country_id = 52790
*sales600 에 country_id 컬럼이 없음.
s.time_id BETWEEN TO_DATE('1999/01/01','YYYY/MM/DD')
AND TO_DATE('1999/12/31','YYYY/MM/DD')
걸어야 할 인덱스:
create index sales600_cust_id
on sales600(cust_id);
create index customers600_cust_id
on customers600(cust_id);
SELECT /*+ leading(c s) use_nl(s) */ COUNT(*)
FROM sales600 s, customers600 c
WHERE s.cust_id = c.cust_id
AND c.country_id = 52790
AND s.time_id BETWEEN TO_DATE('1999/01/01','YYYY/MM/DD')
AND TO_DATE('1999/12/31','YYYY/MM/DD');
문제45. 아래의 sql 의 조인방법은 무조건 nested loop
조인으로 하되
조인 순서를 결정하고 인덱스도 알아서 생성하시오!
튜닝전:
select e.ename, e.sal, d.loc, e.deptno
from emp e, dept d
where e.deptno = d.deptno
and e.job = 'SALESMAN'
and d.loc = 'CHICAGO';
튜닝후:
건수 카운트해서 주석처리
create index emp_deptno
on emp(deptno);
create index dept_deptno
on dept(deptno);
또는 dept 에 primary key 를 걸어서
암시적 인덱스 줄 것
alter table dept
add costraint dept_dpetno_pk primary key(deptno);
select /*+ leading(d e) use_nl(e) */
e.ename, e.sal, d.loc, e.deptno
from emp e, dept d---------14,5
where e.deptno = d.deptno
and e.job = 'SALESMAN'--------4
and d.loc = 'CHICAGO';---------1
문제46. 아래의 조금더 sql을 튜닝하시오
SELECT /*+ leading(c s) use_nl(c) */ COUNT(*)
FROM sales600 s, customers600 c -----918843, 55500
WHERE s.cust_id = c.cust_id
AND c.country_id = 52790 ---------------18520
AND s.time_id BETWEEN TO_DATE('1999/01/01','YYYY/MM/DD')
AND TO_DATE('1999/12/31','YYYY/MM/DD');
----------------247945
걸어야 할 인덱스:
연결고리절↓
create index sales600_cust_id
on sales600(cust_id);
create index customers600_cust_id
on customers600(cust_id);
그리고↓
create index customers600_country_id
on customers600(country_id);
create index sales600_time_id
on sales600(time_id);
문제47. 아래의 sql 을 올바른 hash 조인으로 변경하시오
SELECT /*+ leading(c s) use_hash(c) */
COUNT(*)
FROM sales600 s, customers600 c -----918843, 55500
WHERE s.cust_id = c.cust_id
AND c.country_id = 52790 ---------------18520
AND s.time_id BETWEEN TO_DATE('1999/01/01','YYYY/MM/DD')
AND TO_DATE('1999/12/31','YYYY/MM/DD');
----------------247945

hash 조인은 full 을 타게 해야 한다.
SELECT /*+ leading(c s) use_hash(s) full(c) full(s) */
COUNT(*)
FROM sales600 s, customers600 c -----918843, 55500
WHERE s.cust_id = c.cust_id
AND c.country_id = 52790 ---------------18520
AND s.time_id BETWEEN TO_DATE('1999/01/01','YYYY/MM/DD')
AND TO_DATE('1999/12/31','YYYY/MM/DD');
----------------247945
구글서칭
해시 조인(Hash-Join)은 두 테이블 중 하나를 기준으로
비트맵 해시 테이블을 메모리에 올린 후
나머지 테이블을 스캔 하면서
해싱 테이블을 적용하여 메모리에 로딩된 테이블과 비교하여 매칭되는 데이터를 추출하는 방식의 조인이다.
RDBMS에 서 비용이 가장 많이 들어가는 Join 방법으로
주로 작은 Table과 큰 Table 의 Join 시 사용되어 지며 , Driving 조건과 상관없이 좋은 성능을 발휘할 수 있다.
1. 작은 테이블(Build Input)을 읽어 Hash Area에 해시 테이블 생성한다.
(해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인에 엔트리를 연결)
2. 큰테이블 집합(Probe Input)을 읽어 해시 테이블을 탐색하면서 조인하는 방식이다.
(해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인을 스캔하면서 데이터를 찾는다)
조인 연산 비교
Nested Loop와 Hash Joi의 비교
|
구분 |
Nested loop join |
Hash join |
|
대량의 범위 |
인덱스를 랜덤 액세스에 걸리는 부하가 가장 큰 문제점으로, 최악의 경우 하나의 ROW를 액세스하기 위해 Block단위로 하나하나 액세스를 해야 함. |
적은 집합에 대하여 먼저 해시 값에 따른 Hash Bucket정보를 구성한 후 큰 집합을 읽어 해시 함수를 적용하여 Hash Bucket에 담기 전에 먼저 호가인해 볼 수 있기 때문에 해시조인이 효율적인 수행이 가능 |
|
대량의 자료 |
다량의 랜덤 액세스 수행으로 인해 수행 속도가 저하 |
대용량 처리의 선결조건인 ‘랜덤 액세스’와 ‘정렬’에 대한 문제 개선과 H/W의 성능 개선을 통해 각 조인 집합을 한번 스캔하여 처리하기 때문에 디스크 액세스 면에서 훨씬 효율적 |
■ 해쉬조인의 원리
select /*+ leading(d e) use_hash(e) */
e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno;

※해쉬조인
*해쉬테이블: 메모리로 올라가는 테이블
*탐색테이블: 메모리에 올라가지 않은 테이블
**둘 다 메모리에 올릴 수 없어서
하나만 올라가는데 충분히 빨라진다.
>>>2개 테이블 중 작은 테이블을 메모리로 올려야 한다.
만약 큰 테이블을 올리면 컴퓨터가 나눠서 작업함. 부하.
*****그래서
해쉬조인할 때 leading 순서 잘 정해줘야 한다.******
메모리에 올려서 작업하는 테이블은
풀테이블스캔 해야 한다.
메모리를 통해 풀 떴는데
또 일일이 인덱스찾아서 조인시키고 있는게
더 오래 걸린다.
만약
인덱스가 걸려있으면 힌트절에 풀스캔 하라고 써줄 것.
full(s) 이렇게.
*nested loop 조인은 메모리에 올라가지 않는 테이블
select /*+ leading(d e) use_hash(e) full(d) full(e) */
e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno;
*leading 절 순서는 꼭 지킬 것. (leading(d e) )
*full scan 지시 테이블 힌트절은 순서 상관없이 써도 됨.
(full(e) full(d) )
*hash 쓴 만큼 full sacn 힌트 넣어줄 것.
****
적은 용량 테이블을 메모리에 올려서
해시함수적용 임시테이블을 만든다.
그걸 기반으로 용량 큰 테이블도 풀스캔해서
서로 chain 시켜서 원하는 일치값을
출력하는게
해시함수다.
select /*+ leading(d e) use_hash(e) full(e) full(d) */
e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno
and e.job = 'SALESMAN';
이렇게 조건이 붙으면
조건에서 건수가 적은게 메모리로 올라간다.
즉 조건 salesman 돌렸더니
emp 는 3건
dept 4 건
나오면 emp 를 메모리에 올려서 돌리는게 더 빠르다.
문제48. 아래의 SQL 을 HASH 조인으로 수행되게 한 후
최대한 줄인 블럭 갯수로 검사 받으세요.
select /*+ leading(p s t) use_hash(p) full(p) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p---918843, 1826, 72
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)----731
and p.prod_name like 'Deluxe%'---------1
group by p.prod_name, t.calendar_year;

원래 3개 조인할 거면 연결고리를 2개 설정해줘야 하는데
use_hash(p) 라고 하나만 설정해줬다.
그래서 옵티마이져가 알아서 나머지 한개 조인은
최적으로 골라서 돌린거다.
우용답:
select /*+ leading(p s t) use_hash(p) use_hash(t) full(p) full(t) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)
and p.prod_name like 'Deluxe%'
group by p.prod_name, t.calendar_year;

1.해쉬 수 만큼 full 씀.
2. leading 과 use_hash 가 맞지 않는데도 불구하고
옵티마이져가 알아서 최적으로 수행함.
그래서 index 날라오고, nested 날라오고 그런거임.
select /*+ leading(p s t) use_hash(s) use_hash(t) full(p) full(t) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p---918843, 1826, 72
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)----731
and p.prod_name like 'Deluxe%'---------1
group by p.prod_name, t.calendar_year;
create index products100_name
on products100(prod_name);
create index sales100_prod_id
on sales100(prod_id);
create index products100_prod_id
on products100(prod_id);
create index times100_time_id
on times100(time_id);
create index sales100_time_id
on sales100(time_id);
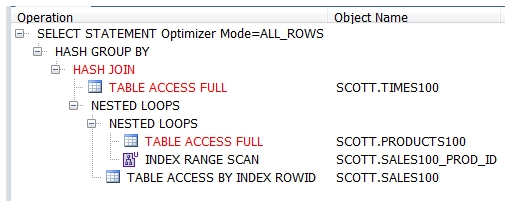
해쉬조인해서 테이블 올라가는게
빨간색.
트리 뷰 해석하면
가장 오른쪽으로 들어가 있는게 먼저 시행되는 것.
문제49. 아래와 같이 실행계획이 나오게 하시오

leading: t s p
use_hash: s p
full: t s p (순서 상관없음)
select /*+ leading(t s p) use_hash(s) use_hash(p)
full(s) full(p) full(t) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p---918843, 1826, 72
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)----731
and p.prod_name like 'Deluxe%'---------1
group by p.prod_name, t.calendar_year;
문제50. 아래와 같이 실행계획이 나오게 하시오

leading: t s p
use_hash: s p
full: 전부
select /*+ leading(t s p) use_hash(s) use_hash(p)
full(s) full(p) full(t) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p---918843, 1826, 72
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)----731
and p.prod_name like 'Deluxe%'---------1
group by p.prod_name, t.calendar_year;
select /*+ leading(t s p) use_hash(s) use_hash(p)
full(s) full(p) full(t)
no_swap_join_inputs(p) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p---918843, 1826, 72
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)----731
and p.prod_name like 'Deluxe%'---------1
group by p.prod_name, t.calendar_year;
P 에 no_swap_join_inputs(p) 해줘서
문제49번 처럼 p에 대한 해쉬함수를 만들지 않고
Full access 만 한다.
※해쉬 조인시 유용한 힌트 2가지?
1.swap_join_inputs : 해쉬 테이블을 지정하는 힌트
2. no_swap_join_inputs: 탐색 테이블을 지정하는 힌트
문제51. 아래와 같이 실행계획이 출력되게 하시오
3개다 테이블 엑세스 풀
leading s t p
해쉬 p, s
select /*+ leading(s t p) use_hash(t) use_hash(p)
full(s) full(p) full(t)
*/
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p---918843, 1826, 72
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)----731
and p.prod_name like 'Deluxe%'---------1
group by p.prod_name, t.calendar_year;
이거 swap 안 걸어도
S에 해쉬함수 걸어서 t랑 체인탐색하고,
그 결과값을 가지고
P에 해쉬함수 걸어서 체인탐색해서 출력.
swap 방법:
select /*+ leading(s t p) use_hash(t) use_hash(p)
full(s) full(p) full(t)
swap_join_inputs(p) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)
and p.prod_name like 'Deluxe%'
group by p.prod_name, t.calendar_year;
트리뷰좀 보여줘봐
문제52. emp와 salgrade 테이블을 조인해서
이름, 월급, 급여등급(grade)을 출력하시오
select e.emp, e.sal, s.grade
from epm e, salgrade s
where e.sal between s.losal and hisal;
*NON EQUI JOIN
문제53. 위의 sql 실행계획을 해쉬조인으로 수행되게 하시오
select /*+ leading (s e) use_hash(e) */
e.ename, e.sal, s.grade
from emp e, salgrade s----------------14,5
where e.sal between s.losal and hisal;
해쉬조인 안된다 !
※해쉬조인은 조인의 연결고리가 =(이퀄) 조건일 때만 가능하다.
만약에 emp 와 salgrade 가 대용량 테이블 이어서
조인 성능이 느리다면 반드시 해쉬조인을 사용해야 하는데
사용 못하는 상황이면 아래와 같이 sort merge join 을
수행해야 한다.
■ 조인 방법 3가지
1. nested loop 조인 : use_nl
2. hash 조인 : use_hash
3. sort merge 조인 : use_merge
■sort merge join 의 원리
" 연결고리가 되는 컬럼의 데이터를 정렬해서
조인하는 조인방법"
"대용량 데이터를 조인할 때 유리한 조인 방법"
sort merge와 Hash join의 비교
|
구 분 |
Sort merge join |
Hash join |
|
조인이 되는 두 테이블의 크기가 다를 경우 |
조인이 되는 두 테이블의 크기가 다르다면 정렬되는 시간이 동일하지 않아 시간에 대한 손실이 발생 |
조인에 대한 알고리즘을 구현하기 때문에 두 집합의 크기가 차이가 나도 대기 시간이 발생치 않음 |
|
대용량 데이터의 경우 |
정렬에 대한 부담 때문에 sort merge조인은 제 기능을 발휘하지 못하는 경우가 발생. 즉 메모리 내의 지정한 정렬 영역보다 정렬할 크기가 지나치게 큰 경우 정렬할 범위가 넓어질수록 효율성을 하락 |
대용량 처리의 선결 조건인 ‘랜덤 액세스’와 ‘정렬’에 대한 문제 개선과 H/W의 성능 개선을 통해 각 조인 집합을 한 번 스캔하여 처리하기 때문에 디스크 액세스 면에서도 훨씬 효율적 |

정렬해서 찾아내려가는 걸 볼 수 있다.
문제54. 아래의 sql 을 작성하는데 조인 순서와 조인 방법이
아래와 같이 되게 하시오!
조인순서: dept ---->emp ------>salgrade
조인방법: hash조인 nl조인
select /*+ leading( d e s ) use_hash(e) use_nl(s)
full(d) full(e) */
e.deptno, e.sal, s.grade
from emp e, dept d, salgrade s----14, 5, 5
where e.deptno = d.deptno
and
e.sal between s.losal and s.hisal;
문제55. 아래의 sql의 조인순서와 조인방법을
아래와 같이 하시오
조인순서: times100--------->sales100------->products100
조인방법: hash nl
select /*+ leading(t s p) use_hash(s) use_nl(p) full(t) full(s) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)
and p.prod_name like 'Deluxe%'
group by p.prod_name, t.calendar_year;

nl 조인에서 시간 많이 잡아먹은걸 확인할 수 있다.
이런걸 확인하고 튜닝들어가야 한다.
문제56. 아래와 같이 실행계획이 나오게 하시오

실행계획에 위와 같이 nested loop 가 두 번이 나오면
인덱스를 통해서 조인한 결과를 메모리에 올려놓고
다음번에 똑같은 결과를 찾으러 조인할 때
테이블 엑세스 안하고 메모리에서 찾아서
출력하겠다는 뜻으로 11g 에서 새로 나온 기능인
advanced nested loop 조인이라고 한다.
select /*+ leading(p s t) use_nl(s) use_hash(t) full(t) */
p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t, products100 p
where s.time_id = t.time_id
and s.prod_id = p.prod_id
and t.CALENDAR_YEAR in (2000,2001)
and p.prod_name like 'Deluxe%'
group by p.prod_name, t.calendar_year;
■outer join 튜닝
-Outer 기호( + )가 붙지 않은 테이블이
항상 Build Input 테이블로 선택된다.
-Leading 이나 Ordered 힌트로 그 순서를 바꿀 수 없다.
select e.ename, d.loc
from emp e, dept d
where e.deptno(+) = d.deptno;
문제57. 위의 조인문의 조인순서와 조인방법을
아래와 같이 되게 하시오
조인순서: dept ---------------> emp
조인방법: hash조인
select /*+ leading(d e) use_hash(e) full(e) */
e.ename, d.loc
from emp e, dept d
where e.deptno(+) = d.deptno;
select /*+ leading(e d) use_hash(d) full(d) */
e.ename, d.loc
from emp e, dept d
where e.deptno(+) = d.deptno;
-Outer 기호( + )가 붙지 않은 테이블이
항상 Build Input 테이블로 선택된다.
***bild input=>해시함수 적용되서 선스캔 되는 테이블.
-Leading 이나 Ordered 힌트로 그 순서를 바꿀 수 없다.
문제58. 아래의 아우터조인의 조인순서와 조인방법을
아래와 같이 되게 하시오
조인순서: dept ---------------> emp
조인방법: hash조인
select /*+ leading(d e ) use_hash(d) full(d) */
e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno(+) ;

근데 자꾸 emp 부터 읽는다.
※설명: 아우터 조인의 조인순서는
항상
아우터 조인 사인이 없는 쪽에서
있는 쪽으로 조인한다.
그리고 order, leading 으로
그 순서를 바꿀 수 없다.
※해쉬 조인시 유용한 힌트 2가지?
1. swap_join_inputs : 해쉬 테이블을 지정하는 힌트
2. no_swap_join_inputs: 탐색 테이블을 지정하는 힌트
>>>>이 힌트를 이용해서
아우터조인 있는 테이블부터
해시함수를 build input 시켜보자.
select /*+ leading(d e ) use_hash(d) full(d)
swap_join_inputs(d) */
e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno(+) ;
문제59. (오늘의 마지막 문제)
아래의 SQL 을 튜닝하시오 !
select t.calendar_year, sum(s.amount_sold)
from sales100 s, times100 t
where s.time_id = t.time_id (+)
and t.week_ending_day_id = 1581
group by t.calendar_year;
select /*+ leading( t s) use_hash(s) full(s)
swap_join_inputs(t) */
t.calendar_year, sum(s.amount_sold)
from sales100 s, times100 t
where s.time_id = t.time_id (+)
and t.week_ending_day_id = 1581
group by t.calendar_year;
create index sales100_time_id on sales100(time_id);
create index times100_time_id on times100(time_id);
create index times100_week_ending_day_id on times100(week_ending_day_id);
select /*+ leading (t s) use_hash(s)
swap_join_inputs(t) */
t.CALENDAR_YEAR, sum(s.amount_sold)
from sales100 s, times100 t
where s.time_id = t.time_id (+)
and t.week_ending_day_id =1581
group by t.calendar_year;
조인 튜닝(sqld 시험에 잘 나옴)
*조인의 방법 3가지
-nested loop 조인 : 조인되는 거수가 얼마 안될 때
사용하는 조인 방법
조인되는 연결고리에 인덱스의 유무에 따라
성능이 크게 차이난다.
**nested loop는 index가 있어야 한다.
-hash 조인: 조인되는 데이터의 양이 대용량 일 떄
사용하는 조인 방법.
인덱스를 엑세스 하기 보다 full table scan 이 오히려
성능상 유리하다.
**index 없고, full scan 해야 한다.
힌트: select /*+ leading(d e) use_hash(e)
full(d) full(e)
parallel (d 4) parallel(e 4) */
>>>혼자서 full scan 힘드니까 4명이서 나눠서 스캔하는건데
병렬구조(parallel)로 나눠서 스캔한다.
** 몇 명까지 분담작업 가능한가?
>>>show parameter cpu_count
최대값은 8 * 2 = 16 이다.(show parameter의 2배가 최대)
16까지 이용 가능하나, 그러면 나혼자 cpu 다 쓰겠다는 뜻이다.
다른사람에게 피해 안가게 4정도가 적당하다.
과부하 가는 튜닝법이라 허락맞고 돌리거나 몰래 돌린다
■12c 로 접속해서 병렬힌트를 썼을 때 실행계획 확인
도스창 키고 12c 접속해서
sqlplus / as sysdba
alter session set container=pdborcl;
connect sys/oracle@localhost:1522/pdborcl as sysdba
alter database pdborcl open;
connect scott/tiger@localhost:1522/pdborcl
set autot traceonly explain
select /*+ leading(d e) use_hash(e)
full(d) full(e)
parallel(d 16) parallel(e 4) */
e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno ;
(보기 힘들면 set pages/lines)
문제60을 예제로 활용하시오.
※설명:
-leading 은 조인 순서를 결정하는 힌트
-use_hash 는 메모리에서 조인하는 해시조인을 유도하는 힌트
-full 은 full table scan 하라고 하는 힌트
-parallel 은 full table scan 을 빠르게 하기 위해
병렬로 작업하라.
-sort merge 조인
4. 서브쿼리 튜닝
5. 기타 튜닝 방법들 소개
문제60. 아래의 sql 을 튜닝하시오
(병렬도 힌트와 full 힌트를 사용해서 작성하시오)
create table sales100
as
select * from sh.sales;
create table times100
as
select * from sh.times;
set timing on
set autot on
select /*+ leading(t s) use_hash(s)
full(t) full(s)
parallel(t 4) parallel(s 4) */
t.calendar_year, sum(s.amount_sold)
from sales100 s , times100 t
where s.time_id = t.time_id(+)
and t.week_ending_day_id = 1581
group by t.calendar_year;
문제61. 아래의 sql 을 튜닝하시오
튜닝전:
select /*+ leading(s t) use_hash(t)
swap_join_inputs(s) */
t.calendar_year, sum(s.amount_sold)
from sales100 s , times100 t-------918843, 1826
where s.time_id = t.time_id(+)
group by t.calendar_year;
튜닝후:
select /*+ leading(t s) use_hash(s)
swap_join_inputs(t)
full(t) full(s)
parallel(t 4) parallel(s 4) */
t.calendar_year, sum(s.amount_sold)
from sales100 s, times100 t
where s.time_id = t.time_id (+)
group by t.calendar_year;
0 db block gets
4498 consistent gets
4433 physical reads
경 과: 00:00:00.63
경 과: 00:00:00.47
경 과: 00:00:00.45
아주 스몰하게 줄어듬......
우리 윈도우시스템 컴퓨터에서는
병렬구조 효과를 보지 못함.
리눅스 운영체제에서는 또 다름.
■ full outer join 튜닝
문제62.
아래의 sql 의 결과를 union all 로 구현하시오!
insert into emp (empno, ename, sal, deptno)
values (1929, 'JACK', 4500, 70 );
select e.ename, d.loc
from emp e full outer join dept d
on (e.deptno = d.deptno) ;
union 구현:
select e.ename, d.loc
from emp e , dept d
where e.deptno(+) = d.deptno
union
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno(+);
*union 특징: 중복제거, 정렬
*full outer join 의 성능이 더 좋음을 알 수 있다.
■11g 가 얼마나 좋은지 옛날것 과 비교해보기.
*선생님이 일부러 옛날버전으로 힌트줘서
출력하게 시키신거임.
select /*+ optimizer_features_enable('10.2.0.1')
opt_param('_optimizer_native_full_outer_join','off') */ e.ename, d.loc
from emp e full outer join dept d
on (e.deptno = d.deptno );

emp, dept 2번씩 스캔하고 난리남.
※힌트설명
▪ optimizer_features_enable('10.2.0.1')----->옵티마이저를
10g 버전으로 사용하겠다.
▪opt_param('_optimizer_native_full_outer_join','off')
---------------------------->full outer join의 성능을
높이는 파라미터를 끄겠다.
*파라미터? 프로그램 옵션같은건데
ex) 카카오톡 알림을 무음으로 하겠다
와 같은 옵션같다.
오라클의 파라미터...그래서 뭔데....
10g 버젼에서의 튜닝후:
select /*+ opt_param('_optimizer_native_full_outer_join','force') */
e.ename, d.loc
from emp e full outer join dept d
on (e.deptno = d.deptno );
문제63. telecom_price 테이블과 우리반 테이블을 조인해서
학생 이름, 나이, 주소, 텔레콤, month_price 를
출력하시오
upDate emp2
set telecom = 'sk'
where telecom = 'SK';
select e.ename, e.age, e.address, e.telecom,
t.month_price
from emp2 e full outer join telecom_price t
on (e.telecom = t.telecom_name);
union 구현:
SELECT e.ename, e.age, e.address, e.telecom,
T.month_PRICE
FROM EMP2 e , TELECOM_PRICE t
WHERE e.telecom(+) = t.telecom_name
UNION
SELECT e.ename, e.age, e.address, e.telecom,
T.month_PRICE
FROM EMP2 e, TELECOM_PRICE t
WHERE e.telecom = t.telecom_name(+);
문제64. 위의 결과에서 통신사가 sk 인 학생들만 출력하시오
(조인튜닝으로 작성하시오)
select /*+ leading(t e) use_nl(e) */
e.ename, e.age, e.address, e.telecom,
t.month_price
from emp2 e , telecom_price t
where e.telecom = t.telecom_name
and e.telecom = 'sk';
땡!
telecom_price 테이블은 sk가 1건이다.
답:
select /*+ leading(t e) use_nl(e) */
e.ename, e.age, e.address, e.telecom,
t.month_price
from emp2 e, telecom_price t
where e.telecom = t.telecom_name
and t.telecom_name = 'sk';
문제65.(점심시간문제)
서일 학생의 이름,나이,통신사,month_price 를
출력하는데 튜닝된 sql 로 작성하시오
(힌트넣으시오)
select /*+ leading(e t ) use_nl(t) */
e.ename, e.age, e.telecom, t.month_price
from emp2 e, telecom_price t
where e.telecom = t.telecom_name
and
e.ename = '서일';
**서일 1건 뽑으니까 emp 테이블 먼저
expand는 grouping sets 레포팅함수용 힌트라서
여기서 쓸 필요 없음.
select /*+ expand_gset_to_union */
e.ename, e.age, e.telecom, t.month_price
from emp2 e, telecom_price t
where e.telecom = t.telecom_name
and
e.ename = '서일';
문제66. 직업이 SALESMAN 이고 부서번호가 30번인
사원의 이름, 월급, 직업, 부서위치를 출력하시오
create index emp_deptno
on emp(deptno);
create index dept_deptno
on dept(deptno);
select /*+ leading (d e) use_nl(e) */
e.ename, e.sal, e.job, d.loc
from emp e, dept d------------14, 5
where e.deptno = d.deptno
and e.job = 'SALESMAN'--------------EMP 4건
and d.deptno = 30;--------dept 1건
문제67번 풀기전에
create table bonus
as
select empno, sal * 1.2 as bonus
from emp;
문제67. 사원이름이 ALLEN 인 사원의
이름, 월급, 부서위치, 보너스를 출력하시오
(조인튜닝 힌트를 사용하시오)
select /*+ leading(e d b) use_nl(d) use_nl(b) */
e.ename, e.sal, d.loc, b.bonus
from emp e, dept d, bonus b-----14, 5, 15
where e.deptno = d.deptno
and e.empno = b.empno
and e.ename = 'ALLEN';------------1
연결고리에 다 인덱스 있어야 하고
emp테이블의 ename에도 인덱스 걸면 더 빨라진다.
++유니크 컬럼 데이터는 primary key 로 걸어주는게 더빠르다.
empno 에는 alter/add constraint 하는게 성능 업.
■ANTI JOIN
이것도 SEMI 인데
IN 이 아닌 NOT IN을 서브 연결자로 쓸 때
사용하는 조인이다.
문제78. 관리자가 아닌 사원들의 이름을 출력하시오
select ename
from emp
where empno not in (select nvl(mgr, -1)
from emp
where mgr is not null);
HASH ANTI JOIN
NOT IN 을 사용했는데 서브쿼리가 대용량이면
HASH ANTI JOIN을 쓴다.
select ename
from emp
where empno not in (select /*+ unnest hash_aj */
nvl(mgr, -1)
from emp
where mgr is not null);
**HASA ANTI 조인 쓰라고 힌트 넣어주는거
문제79. 아래의 sql 을 해시 안티 조인이 되게 하시오
select *
from dept
where deptno not in ( select
deptno
from emp);
답>>
select *
from dept
where deptno not in ( select /*+ unnest hash_aj */
deptno
from emp);
문제80. 위의 sql 의 실행계획이 아래와 같이 되게 하시오.
select *
from emp
where deptno not in ( select /*+ swap_join_inputs(d) */
nvl(deptno, -1)
from dept d
where deptno is not null)
and deptno is not null;
※해시 안티 조인을 하려면
연결고리가 되는 컬럼에
null 이 없다는 조건을 걸어줘야 한다.
※해시 안티 조인은?
세미조인처럼 완전한 조인이 아니라 절반의 조인인데
즉, 메인쿼리의 테이블부터 엑세스 하고
서브쿼리의 테이블을 엑세스 하는 고정된 조인순서를
갖는 실행계획인데
in 이 아니라 not in을 사용한 경우의 실행계획이다.
'sql_tuning' 카테고리의 다른 글
| 5. 파티셔닝 (0) | 2019.04.02 |
|---|---|
| 4. 서브쿼리 튜닝 (0) | 2019.04.02 |
| 2-1. 인덱스 엑세스 방법 (0) | 2019.04.02 |
| 2. 인덱스 튜닝 (0) | 2019.04.02 |
| 1. sql 튜닝이란 무엇이고 왜 배워야 하는가? (0) | 2019.04.02 |


