■ 연관규칙 353p
-쿠팡의 물류센터 예

*연관규칙?
분유와 맥주와의 관계를 알아낸 대표적인 기계학습 방법
*관련된 알고리즘 ---> Apriori 알고리즘
*Apriori 알고리즘?
간단한 성능 측정치를 이용해 거대한 DB에서 데이터간의
연관성을 찾는 알고리즘
*Apriori 알고리즘은 어떤 데이터의 패턴을 찾을 때 유용한가?
1) 암데이터에서 빈번히 발생하는 DNA 패턴과 단백질의 서열을 검색할 때
2) 사기성 신용카드 및 보험의 이용과 결합되어 발생하는 구매 또는
의료비 청구의 패턴 발견
*연관규칙을 사람이 하기 어려운 이유가 무엇인가?(356p)
아이템의 집합을 아이템의 갯수만큼 만들려면
아이템의 갯수를 k라고 하면 2의 k승 개의 아이템 집합이 생성되는데
아이템이 100개면 2의 100승 개의 아이템 집합이 생기므로
사람이 그 많은 데이터를 직접 분석하기 어렵다.
*연관 규칙에서 사용하는 두 가지 통계 척도가 무엇인가?(359p)
1) 지지도?
특정 아이템이 데이터에서 발생하는 빈도
count(x) <------아이템 x의 거래건수
support(x) = ------------
N <------데이터베이스의 전체 거래 건수
2) 신뢰도?
예측능력이나 정확도의 측정치
support(x,y) <----x,y를 포함하는 아이템 집합의 지지도를
confidence(x->y) = ------------------
support(x) <---x만 포함하는 아이템 집합의 지지도로 나눔
Transaction ID Items Bought
1 우유, 버터, 시리얼
2 우유, 시리얼
3 우유, 빵
4 버터, 맥주, 오징어
지지도(우유-,시리얼) ? 우유와 시리얼을 동시에 구매할 확률(결합확률)
(우유&시리얼) / 전체
신뢰도(우유->시리얼)? 우유를 구매할 때 시리얼도 같이 구매할 조건부확률
지지도{ (우유&시리얼) } / 지지도(우유)
*전체 아이템에서 우유와 시리얼이 동시에 출현될 확률은?
전체 4건에서 우유+시리얼이 있는건 1,2
그래서 2/4 => 1/2 (50%)
*우유를 샀을 때, 시리얼을 구매 할 조건부확률은?
우유구매한 3건에서 시리얼이 포함된 게 2건이라서
2/3 (66%)
*이와는 반대로 시리얼을 샀을 때 우유를 동시에 구매할 확률은?
2/2 (100%)
*우유와 시리얼을 샀을 때 지지도와 신뢰도를 각각 구하시오
|
|
지지도 |
신뢰도 |
|
우유->시리얼 |
50% |
66% |
|
시리얼->우유 |
50% |
100% |
지지도는 전체에 대한 x의 확률
신뢰도는 x에 대한 y의 확률
x와 y의 지지도와 신뢰도를 구하는데 모든 아이템들에 대해서 다 지지도와
신뢰도를 구한다
그 중에 최소 지지도 이상인 데이터만 필터링하고서
필터링 된 것 중에 신뢰도가 가장 좋은 것을 찾는다.
*어떻게 필터링 하는가?
TID Items
100 A C D
200 B C E
300 A B C E
400 B E
*위의 아이템에 대해서 지지도를 산정해 보시오!
원래 지지도는 구매건수/전체 구매건수 로 계산할 수 있지만
여기서는 단순하게 아이템 갯수로 처리하시오
전체에서 각 아이템이 등장한 횟수를 카운트 해본다
|
아이템 |
지지도 |
|
A |
2 |
|
B |
3 |
|
C |
3 |
|
D |
1 |
|
E |
3 |
*이것에 대해서 지지도가 1보다 큰 것만 추출해서 다시 정리하시오
|
아이템 |
지지도 |
|
A |
2 |
|
B |
3 |
|
C |
3 |
|
E |
3 |
*이제 아이템들간의 연관규칙을 알아야하므로 다시 아이템들간의
조합으로 재구성하고 지지도를 다시 구하시오
TID Items
100 A C D
200 B C E
300 A B C E
400 B E
|
아이템 |
아이템 |
지지도 |
|
A |
B |
1 |
|
A |
C |
2 |
|
A |
E |
1 |
|
B |
C |
2 |
|
B |
E |
3 |
|
C |
E |
2 |
|
D |
E |
0 |
*위 결과에서 지지도가 2 이하 인 것을 제외시키시오
|
아이템 |
아이템 |
지지도 |
|
A |
C |
2 |
|
B |
C |
2 |
|
B |
E |
3 |
|
C |
E |
2 |
*이제 각각의 아이템 목록에서 첫번 째 아이템을 기준으로 동일한 것을
찾아보시오
|
아이템 |
아이템 |
지지도 |
|
A |
C |
2 |
|
B |
C |
2 |
|
B |
E |
3 |
|
C |
E |
2 |
TID Items
100 A C D
200 B C E
300 A B C E
400 B E
░ 2개 알파벳에 대한 모든 경우의 수를 분류시키고
등장 횟수가 가장 많은 것을 연관규칙 값으로 정한다.
■ Apriori 알고리즘 예제1 (맥주와 기저귀)
"맥주와 기저귀 판매 목록 데이터를 가지고 기저귀를 사면 맥주를
산다는 연관 규칙을 발견하시오!"
1. 데이터프레임 생성하기
x <- data.frame(
beer=c(0,1,1,1,0),
bread=c(1,1,0,1,1),
cola=c(0,0,1,0,1),
diapers=c(0,1,1,1,1),
eggs=c(0,1,0,0,0),
milk=c(1,0,1,1,1) )
2. arules 패키지를 설치한다
install.packages("arules")
library(arules)
trans<- as.matrix(x, "Transaction")
trans
trans
beer bread cola diapers eggs milk
[1,] 0 1 0 0 0 1
[2,] 1 1 0 1 1 0
[3,] 1 0 1 1 0 1
[4,] 1 1 0 1 0 1
[5,] 0 1 1 1 0 1
3. Apriori 함수를 이용해서 연관관계를 분석한다
rules1<-apriori(trans, parameter=list(supp=0.2, conf=0.6,
+ target="rules"))
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen maxlen
0.6 0.1 1 none FALSE TRUE 5 0.2 1 10
target ext
rules FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 1
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[6 item(s), 5 transaction(s)] done [0.00s].
sorting and recoding items ... [6 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 4 done [0.00s].
writing ... [49 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].
rules1
set of 49 rules
inspect(sort(rules1))
지지도 신뢰도 lift count
[5] {beer} => {diapers} 0.6 1.0000000 1.2500000 3
[6] {diapers} => {beer} 0.6 0.7500000 1.2500000 3
[7] {milk} => {bread} 0.6 0.7500000 0.9375000 3
[8] {bread} => {milk} 0.6 0.7500000 0.9375000 3
[9] {milk} => {diapers} 0.6 0.7500000 0.9375000 3
[10] {diapers} => {milk} 0.6 0.7500000 0.9375000 3
[11] {bread} => {diapers} 0.6 0.7500000 0.9375000 3
[12] {diapers} => {bread} 0.6 0.7500000 0.9375000 3
[13] {cola} => {milk} 0.4 1.0000000 1.2500000 2
[14] {cola} => {diapers} 0.4 1.0000000
※ 설명 : 신뢰도가 클수록 연관관계가 높다는 의미이다.
lift(향상도) 는 상관관계를 나타낸다.
연관규칙을 평가하는 지수는 지지도, 신뢰도 말고도 많은데
그중에 꽤 많이 쓰이는것이 lift(향상도) 이다.
* 위의 맥주와 기저귀 연관 관계를 시각화 하기
install.packages("sna")
install.packages("rgl")
library(sna)
library(rgl)
#visualization
b2 <- t(as.matrix(trans)) %*% as.matrix(trans)
library(sna)
library(rgl)
b2.w <- b2 - diag(diag(b2))
#rownames(b2.w)
#colnames(b2.w)
gplot(b2.w , displaylabel=T , vertex.cex=sqrt(diag(b2)) , vertex.col = "green" , edge.col="blue" , boxed.labels=F , arrowhead.cex = .3 , label.pos = 3 , edge.lwd = b2.w*2)

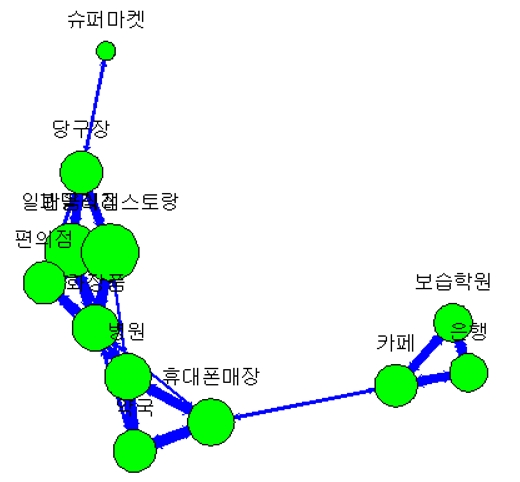
※ 선이 굵을수록 연관성이 높다.
문제251.
상가 건물 데이터의 연관성 분석을 하고 시각화를 하시오
건물 상가에 서로 연관이 있는 업종이 무엇인가?
건물에 병원이 있으면 약국이 있는가?
"보습학원이 있는 건물에는 어떤 업종의 매장이 연관되어 있는지
찾아내시오!"
build <- read.csv("building.csv" , header = T)
build[is.na(build)] <- 0
names(build)
build <- build[-1]
names(build )
#install.packages("arules")
library(arules)
trans <- as.matrix(build , "Transaction")
rules1 <- apriori(trans , parameter = list(supp=0.2 , conf = 0.6 , target = "rules"))
rules1
rules1
set of 46 rules
inspect(sort(rules1))
#visualization
b2 <- t(as.matrix(trans)) %*% as.matrix(trans)
library(sna)
library(rgl)
b2.w <- b2 - diag(diag(b2))
#rownames(b2.w)
#colnames(b2.w)
gplot(b2.w , displaylabel=T ,
vertex.cex=sqrt(diag(b2)) ,
vertex.col = "green" , edge.col="blue" ,
boxed.labels=F , arrowhead.cex = .3 , label.pos = 3 ,
edge.lwd = b2.w*2)
■ 영화 라라랜드의 긍정적 평가와 부정적 평가에 대한
워드 클라우드를 그리고 연관성 분석을 하는 테스트
1. 라라랜드 데이터를 로드한다.
Sys.setenv(JAVA_HOME='C:\\Program Files\\Java\\jre1.8.0_201')
install.packages("rJava")
library(rJava)
library(KoNLP)
library(wordcloud)
lala <- read.csv('라라랜드.csv', header=T, stringsAsFactors = F)
2. 영화평점이 9점이상은 긍정변수넣고 2점 이하는 부정변수에 넣는다
lala_positive <- lala[lala$score>=9,c('content')]
lala_negative <- lala[lala$score<=2,c('content')]
head(lala_positive)
head(lala_negative)
3. 긍정게시판 변수에서 명사만 추출하고 데이터 정제 작업을 한다.
po <- sapply(lala_positive, extractNoun, USE.NAMES=F)
po2 <- unlist(po)
po2 <- Filter(function(x){nchar(x)>=2},po2)
po3 <- gsub('\\d+','',po2)
po3 <- gsub('관람객','',po3)
po3 <- gsub('평점', '', po3)
po3 <- gsub('영화', '', po3)
po3 <- gsub('진짜', '', po3)
po3 <- gsub('완전', '', po3)
po3 <- gsub('시간', '', po3)
po3 <- gsub('올해', '', po3)
po3 <- gsub('장면', '', po3)
po3 <- gsub('남자', '', po3)
po3 <- gsub('여자', '', po3)
po3 <- gsub('만큼', '', po3)
po3 <- gsub('니가', '', po3)
po3 <- gsub('년대', '', po3)
po3 <- gsub('옆사람', '', po3)
po3 <- gsub('들이', '', po3)
po3 <- gsub('저녁', '', po3)
write(unlist(po3), 'lala_positive.txt')
po4 <- read.table('lala_positive.txt')
po_wordcount <- table(po4)
4. 라라랜드 영화에 부정적인 평가 게시글들 명사로 변경하고
정재 작업을 수행한다.
ne <- sapply(lala_negative, extractNoun, USE.NAMES=F)
ne2 <- unlist(ne)
ne2 <- Filter(function(x){nchar(x)>=2},ne2)
ne3 <- gsub('\\d+','',ne2)
ne3 <- gsub('관람객','',ne3)
ne3 <- gsub('평점', '', ne3)
ne3 <- gsub('영화', '', ne3)
ne3 <- gsub('진짜', '', ne3)
ne3 <- gsub('완전', '', ne3)
ne3 <- gsub('시간', '', ne3)
ne3 <- gsub('올해', '', ne3)
ne3 <- gsub('장면', '', ne3)
ne3 <- gsub('남자', '', ne3)
ne3 <- gsub('여자', '', ne3)
ne3 <- gsub('만큼', '', ne3)
ne3 <- gsub('니가', '', ne3)
ne3 <- gsub('년대', '', ne3)
ne3 <- gsub('옆사람', '', ne3)
ne3 <- gsub('들이', '', ne3)
ne3 <- gsub('저녁', '', ne3)
write(unlist(ne3), 'lala_negative.txt')
ne4 <- read.table('lala_negative.txt')
ne_wordcount <- table(ne4)
5. 긍정 단어와 부정단어를 각각 워드 클라우드로 그려서 한 화면에
출력한다.
graphics.off()
palete <- brewer.pal(9,'Set1')
par(new=T, mfrow=c(1,2))
wordcloud(names(po_wordcount), freq=po_wordcount, scale=c(3,1), rot.per=0.1, random.order = F,
random.color = T, col=rainbow(15))
title(main='라라랜드의 긍정적인 평가', col.main='blue')
wordcloud(names(ne_wordcount), freq=ne_wordcount, scale=c(3,1), rot.per=0.1, random.order = F,
random.color = T, col=rainbow(15))
title(main='라라랜드의 부정적인 평가', col.main='red')

문제252. 라라랜드의 긍정적 평가 게시판의 글들을 명사만
추출한 다음 단어들간의 연관관계를 출력하시오
답 :
1. 관련된 패키지 설치
library(KoNLP)
library(wordcloud)
library(tm)
library(stringr)
library(arules)
2. 명사 추출하는 코드
lala_positive <- sapply(lala_positive, extractNoun, USE.NAMES=F)
head(lala_positive)
3. unlist 로 변환한후에 철자가 2개이상이고 5개 이하인
것만 추출
c <- unlist(lala_positive)
lala_positive2 <- Filter(function(x) { nchar(x) >= 2 &
nchar(x) <= 5 } , c)
4. 데이터 정재작업( 분석하기에 너무 많이 나오는 단어를
삭제하는 작업 )
# 숫자제거
lala_positive2 <- gsub('\\d+','',lala_positive2)
lala_positive2 <- gsub('관람객','',lala_positive2)
lala_positive2 <- gsub('평점', '', lala_positive2)
lala_positive2 <- gsub('영화', '', lala_positive2)
lala_positive2 <- gsub('진짜', '', lala_positive2)
lala_positive2 <- gsub('완전', '', lala_positive2)
lala_positive2 <- gsub('시간', '', lala_positive2)
lala_positive2 <- gsub('올해', '', lala_positive2)
lala_positive2 <- gsub('장면', '', lala_positive2)
lala_positive2 <- gsub('남자', '', lala_positive2)
lala_positive2 <- gsub('여자', '', lala_positive2)
lala_positive2 <- gsub('만큼', '', lala_positive2)
lala_positive2 <- gsub('니가', '', lala_positive2)
lala_positive2 <- gsub('년대', '', lala_positive2)
lala_positive2 <- gsub('옆사람', '', lala_positive2)
lala_positive2 <- gsub('들이', '', lala_positive2)
lala_positive2 <- gsub('저녁', '', lala_positive2)
lala_positive2 <- gsub('영화', '', lala_positive2)
lala_positive2
5. 한글이 아닌 데이터를 제거하는 작업
res <- str_replace_all(lala_positive2, "[^[:alpha:]]","")
6. "" 데이터 제거하는 작업
res <- res[res != ""]
7. 단어와 그 건수를 출력하는 작업
wordcount <- table(res)
wordcount2 <- sort( table(res), decreasing=T)
8. 단어의 건수가 100 보다 큰것만 필터링
keyword <- names( wordcount2[wordcount2>100] )
length(lala_positive)
9. 아프리오리 분석을 위해서 표형태로 만드는 작업
contents <- c()
for(i in 1:length(lala_positive)) {
inter <- intersect(lala_positive[[i]] , keyword)
contents <- rbind(contents ,table(inter)[keyword])
}
10. 표의 컬럼명에 단어가 들어가게한다.
colnames(contents) <- keyword
11. na 를 숫자 0 으로 변경한다.
contents[which(is.na(contents))] <- 0
dim(lala_positive)
12. 아프리오리 데이터 분석
detach(package:tm, unload=T)
library(arules)
rules_lala <- apriori(contents , parameter = list(supp = 0.007 , conf = 0.3 , target = "rules"))
rules_lala
rules_lala
set of 10 rules
inspect(sort(rules_lala ))
inspect(sort(rules_lala ))
lhs rhs support confidence lift count
[1] {영상} => {음악} 0.020449109 0.6354916 5.285838 265
[2] {연기} => {음악} 0.016282121 0.5158924 4.291046 211
[3] {스토리} => {음악} 0.016204954 0.4708520 3.916413 210
[4] {영상미} => {음악} 0.014352959 0.4124169 3.430366 186
[5] {배우} => {음악} 0.012655297 0.4795322 3.988612 164
[6] {배우} => {연기} 0.011574967 0.4385965 13.896753 150
[7] {연기} => {배우} 0.011574967 0.3667482 13.896753 150
[8] {눈빛} => {마지막} 0.009414307 0.6777778 8.908035 122
[9] {연출} => {음악} 0.007716645 0.3861004 3.211473 100
[10] {색감} => {음악} 0.007407979 0.4247788 3.533189 96


