■ 랜덤 포레스트(p 493)
random forest 는 "decision tree" 와 "bagging" 을 결합한 알고리즘
■ Bagging 484p
부트스트랩 집계 bootstrap aggregating의 약자.
"샘플을 여러 번 뽑아 각 모델을 학습시켜 결과를 집계 하는 방법"
다른 앙상블 기반의 방법들과 비교해서 랜덤 포레스트는
매우 경쟁력이 있고 사용하기 쉽고 쉽게 과적합 되지 않는다.
|
장점 |
단점 |
|
모든 문제에 대해 잘 수행되는 다목적 모델이다 |
의사결정 트리 같지 않게 모델 해석이 쉽지 않다 |
|
범주형 또는 연속 특징 뿐 아니라 잡음이 있는 데이터나 누락 데이터 (결측치)를 다룰 수 있다 |
모델을 데이터에 맞춰 튜닝하려면 약간의 작업이 필요할 수 있다 |
|
가장 중요한 특징만을 선택한다 |
|
|
극도로 큰 개수의 특징이나 예시가 있는 데이터에 사용될 수 있다 |
|
예제: 독일채무 불이행자를 예측하는 랜덤포레스트 모델 생성
install.packages("randomForest")
library(randomForest)
credit<-read.csv("credit.csv")
set.seed(300)
rf<-randomForest(default~., data=credit)
rf
credit_predict<-predict(rf, credit)
table(credit_predict, credit$default)
credit_predict no yes
no 700 0
yes 0 300
문제269.
소아 척추 수술에 대한 데이터를 이용해서 척추병의 완치를
예측하는 모델을 생성하시오
실습 :
kyphosis 데이터는 성형외과에서 아이들이 척추수술후에
얼마만에 증상이 사라졌는지 아니면 그대로 존재하는지에
대한 데이터로서 독립변수가 처음 수술한 척추의 수와
관련된 척추의 수 그리고 경과 개월이다.
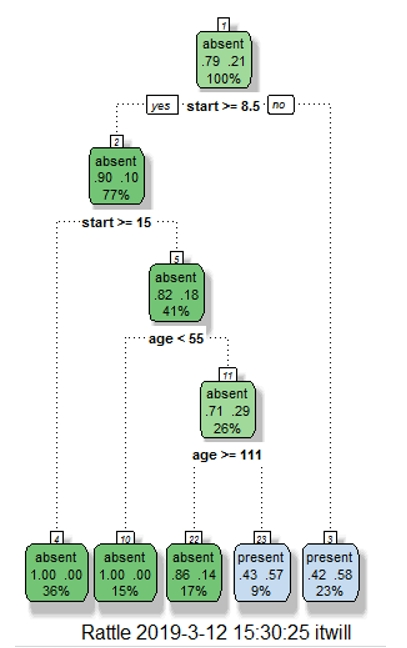
데이터가 81개 밖에 안되니 그냥 결정트리에 넣어서
예측과 실제 라벨을 비교해서 정확도를 보자
1. 데이터를 로드한다.
kyphosis <- read.csv("kyphosis.csv")
View(kyphosis)
2. rpart 를 이용해서 결정트리 모델을 생성한다.
library(rpart)
fit <- rpart(kyphosis ~ age + number + start,method="class",
data=kyphosis)
3. 모델을 시각화 한다.
install.packages("rpart")
install.packages("rattle")
library(rattle)
library(rpart.plot)
fancyRpartPlot(fit)
화면 캡처: 2019-03-12 오후 3:31
4. 정확도를 확인한다.
result <- predict(fit , kyphosis)
sum(kyphosis$kyphosis == ifelse(result[,1]>0.5 ,
"absent" , "present"))/NROW(ky)
0.8395062
문제270.
랜덤포레스트를 이용해서 위의 정확도를 올리는 모델을 생성하시오
library(randomForest)
ky<-read.csv("kyphosis.csv")
fit <- randomForest(kyphosis ~ age + number + start,
data=ky)
res2 <- predict(fit , ky)
sum(res2 == ky$kyphosis)/NROW(ky)
0.9753086
'R' 카테고리의 다른 글
| 서포트 벡터 머신 (0) | 2019.04.17 |
|---|---|
| 특화된 머신러닝 주제 (0) | 2019.04.17 |
| 모델성능개선 부스팅, 앙상블,배깅 (0) | 2019.04.17 |
| 모델 성능개선 (0) | 2019.04.03 |
| 모델 성능평가 (0) | 2019.04.03 |


