■ 특화된 머신러닝 주제
1. 소셜 네트워크 분석 시각화
2. 병렬처리로 데이터 분석 속도는 높이는 방법
■ 소셜 네트워크 분석 시각화 (p523)
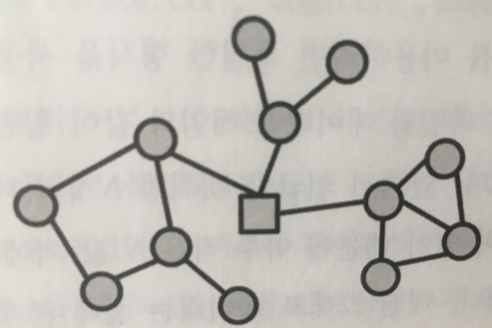
네트워크 분석?
사람이나 사물, 조직, 기술, 자원들의 연결관계 속에서 핵심적인 기능을
담당하는 행위주체를 판별/발굴하고
보다 효과적인 인력/자원 활용 및 조직화 방안을 분석하는 기법
░ 네트워크 분석이 활용되는 분야
1. 생물 유전학의 유전자 데이터 시각화 ( 암 연구센터 )
2. 사회망 관계 시각화 ( 사회과학 )
3. 금융 사기 예방
*실습예제
학생들의 교류 패턴을 연구하고자 한다. 누가 누구와 주로 이야기를 하고
식사를 하고 전화를 할까?
한번도 얘기를 안 하는 사람도 있을 것이고 자주 얘기를 하는 사람도 있을 것인데
누가 가장 사회성이 좋을까?
질문: 학생들의 사회적 척도에 미치는 영향 중에 한 달 평균 독서량과
어떤 관계가 있는지?
1. 데이터를 로드한다
paper <- read.csv("paper1.csv")
2. na를 0으로 변경한다
paper[is.na(paper)]<-0
3. 컬럼인 이름을 row 의 이름으로 설정한다
rownames(paper)<-paper[,1] # paper의 1열 내용을 rownames 로 !
paper<-paper[-1] # x 값 제거
# 그럼 이제 rowname 과 column name 이 일치한다.
4. 행렬형태로 변환한다
paper2<- as.matrix(paper)
5. 한 달에 읽은 책의 갯수
book<-read.csv("book_hour.csv", header=T)
paper2
book
library(sna)
6. 새로운 창을 열어서 거기에 그래프를 그린다.
gplot(paper2 , displaylabels = T, boxed.labels = F , vertex.cex = sqrt(book[,2]) , vertex.col = "blue" , vertex.sides = 20 ,
edge.lwd = paper2*2 , edge.col = "green" , label.pos = 3)
# vertex.cex 원의 크기

문제271.
우리반에서 이번주에 같이 밥먹은 학생 데이터로 시각화를 하시오
meal<-read.csv("emp2_meal.csv")
head(meal)
meal[is.na(meal)]<-0
rownames(meal)<-meal[,1]
meal<-meal[-1]
head(meal)
meal<-as.matrix(meal)
head(meal)
library(sna)
gplot(meal , displaylabels = T, boxed.labels = F , vertex.col = "blue" , vertex.sides = 20 ,
edge.lwd = meal*2 , edge.col = "green" , label.pos = 3)
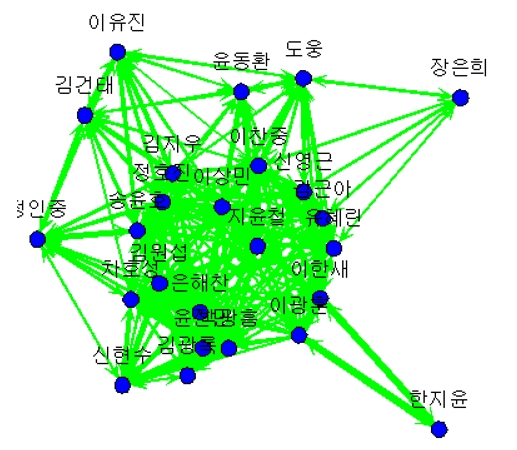
문제272.
emp8_meal.csv 로 sns 를 그리시오
meal<-read.csv("emp8_meal.csv")
head(meal)
meal[is.na(meal)]<-0
rownames(meal)<-meal[,1]
head(meal)
meal<-meal[-1]
head(meal)
meal<-as.matrix(meal)
head(meal)
library(sna)
gplot(meal , displaylabels = T, boxed.labels = F , vertex.col = "blue" , vertex.sides = 20 ,
edge.lwd = meal*2 , edge.col = "green" , label.pos = 3)

문제272.
레미제라블 장발장 소설의 인물관계도를 시각화 하시오
###################전체 코드################################
library(networkD3)
library(dplyr)
# data set 소설 레미제라블 인물 관계도
data(MisLinks, MisNodes)
head(MisNodes) # 인물
head(MisNodes)
name group size
1 Myriel 1 15
2 Napoleon 1 20
3 Mlle.Baptistine 1 23
4 Mme.Magloire 1 30
5 CountessdeLo 1 11
6 Geborand 1 9
head(MisLinks) # 관계
head(MisLinks)
source target value
1 1 0 1
2 2 0 8
3 3 0 10
4 3 2 6
5 4 0 1
6 5 0 1
# plot
D3_network_LM<-forceNetwork(Links = MisLinks, Nodes = MisNodes,
Source = 'source', Target = 'target',
NodeID = 'name', Group = 'group',opacityNoHover = TRUE,
zoom = TRUE, bounded = TRUE,
fontSize = 15,
linkDistance = 75,
opacity = 0.9)
D3_network_LM

# html 발사
networkD3::saveNetwork(D3_network_LM, "D3_LM.html", selfcontained = TRUE)
문제273.
7기 데이터를 가지고 웹페이지에서 네트워크 관계도가 출력되게 하시오
library(networkD3)
library(dplyr)
emp7<- read.csv("emp2_node_df.csv")
head(emp7)
# idx는 그냥 번호 붙여준것
emp_link<-read.csv("link_emp2.csv")
head(emp_link)
# sorce_idx는 source 의 idx
# data set 소설 레미제라블 인물 관계도
data(emp_link, emp7)
head(MisNodes)
head(MisLinks)
# plot
D3_network_LM<-forceNetwork(Links = emp_link, Nodes = emp7,
Source = 'source_idx', Target = 'target_idx',
NodeID = 'node',Group='idx', opacityNoHover = TRUE,
zoom = TRUE, bounded = TRUE,
fontSize = 15,
linkDistance = 75,
opacity = 0.9)
D3_network_LM
문제274.
아이티 글로벌 기업들간의 재판소송 현황을 시각화하시오
links = '[
{"source": "Microsoft", "target": "Amazon", "type": "licensing"},
{"source": "Microsoft", "target": "HTC", "type": "licensing"},
{"source": "Samsung", "target": "Apple", "type": "suit"},
{"source": "Motorola", "target": "Apple", "type": "suit"},
{"source": "Nokia", "target": "Apple", "type": "resolved"},
{"source": "HTC", "target": "Apple", "type": "suit"},
{"source": "Kodak", "target": "Apple", "type": "suit"},
{"source": "Microsoft", "target": "Barnes & Noble", "type": "suit"},
{"source": "Microsoft", "target": "Foxconn", "type": "suit"},
{"source": "Oracle", "target": "Google", "type": "suit"},
{"source": "Apple", "target": "HTC", "type": "suit"},
{"source": "Microsoft", "target": "Inventec", "type": "suit"},
{"source": "Samsung", "target": "Kodak", "type": "resolved"},
{"source": "LG", "target": "Kodak", "type": "resolved"},
{"source": "RIM", "target": "Kodak", "type": "suit"},
{"source": "Sony", "target": "LG", "type": "suit"},
{"source": "Kodak", "target": "LG", "type": "resolved"},
{"source": "Apple", "target": "Nokia", "type": "resolved"},
{"source": "Qualcomm", "target": "Nokia", "type": "resolved"},
{"source": "Apple", "target": "Motorola", "type": "suit"},
{"source": "Microsoft", "target": "Motorola", "type": "suit"},
{"source": "Motorola", "target": "Microsoft", "type": "suit"},
{"source": "Huawei", "target": "ZTE", "type": "suit"},
{"source": "Ericsson", "target": "ZTE", "type": "suit"},
{"source": "Kodak", "target": "Samsung", "type": "resolved"},
{"source": "Apple", "target": "Samsung", "type": "suit"},
{"source": "Kodak", "target": "RIM", "type": "suit"},
{"source": "Nokia", "target": "Qualcomm", "type": "suit"}
]'
link_df = jsonlite::fromJSON(links)
# node의 index 숫자는 0부터 시작해야 한다
# dplyr::row_number()가 1부터 숫자를 매기기 때문에 거기서 1씩을 빼도록 한다
node_df = data.frame(node = unique(c(link_df$source, link_df$target))) %>%
mutate(idx = row_number()-1)
# node_df에서 index값을 가져와서 source와 target에 해당하는 index 값을 저장한다
link_df = link_df %>%
left_join(node_df %>% rename(source_idx = idx), by=c('source' = 'node')) %>%
left_join(node_df %>% rename(target_idx = idx), by=c('target' = 'node'))
# 데이터 확인
node_df
link_df
library(networkD3)
library(dplyr)
D3_network_LM<-forceNetwork(Links = link_df,
Nodes = node_df,
Source = 'source_idx', Target = 'target_idx',
NodeID = 'node', Group = 'idx',
opacityNoHover = TRUE, zoom = TRUE,
bounded = TRUE,
fontSize = 15,
linkDistance = 75,
opacity = 0.9)
D3_network_LM

문제275. 우리반 데이터로 D3_network_LM 을 그리시오
library(networkD3)
library(dplyr)
emp8_node_df<- read.csv("emp8_node_df.csv")
head(emp8_node_df)
# idx는 그냥 번호 붙여준것
link_emp8<-read.csv("link_emp8.csv", fileEncoding="UTF8" )
head(link_emp8)
# sorce_idx는 source 의 idx
# plot
D3_network_LM<-forceNetwork(Links = link_emp8, Nodes = emp8_node_df,
Source = 'source_idx', Target = 'target_idx',
NodeID = 'node',Group='idx', opacityNoHover = TRUE,
zoom = TRUE, bounded = TRUE,
fontSize = 15,
linkDistance = 75,
opacity = 0.9)
D3_network_LM
■ R 에서의 병렬처리(537p)
**과거 직렬 컴퓨팅
**현재 병렬 컴퓨팅

작업관리자-성능- CPU 사용현황의 검정+초록 창 갯수가 core 갯수다
(즉 동시 작업처리 가능한 갯수)
■ R 에서의 명령어의 수행시간 확인하는 방법
system.time(rnorm(1000000))
사용자 시스템 elapsed
0.08 0.00 0.08
**내 코드의 실행시간과 시스템의 실행시간을 비교해서
평상시에 잘 돌던 내 코드가 오늘따라 유독 느리다면 시스템 시간을
확인해봐야 한다.
▣ foreach 와 doParallel 을 이용해서 병렬로 작업하는 방법
** foreach 가 직렬!
library(foreach)
system.time(
a<-foreach(i=1:4, .combine='c')%do% rnorm(250000)
)
사용자 시스템 elapsed
0.07 0.01 0.11
**doParallel 병렬
library(doParallel)
registerDoParallel(cores=4)
system.time(b<-foreach(i=1:4, .combine='c')%do% rnorm(250000))
사용자 시스템 elapsed
0.06 0.00 0.06
stopImplicitCluster()
**545p 병렬클러스터를 닫는 명령어


